Large Language Models

Large Language Models: Powering the Future of AI Communication
Large Language Models (LLMs) have evolved from research experiments into core infrastructure for software, services, and science, marking a shift where natural language itself becomes a primary interface to computation. By framing intent in words, users can summon plans, queries, code, or explanations, thanks to systems that transform language into structured action. While their apparent magic rests on the scaling of next-token prediction across vast datasets and compute, true usefulness comes from more than size alone: disciplined training, curated data, alignment with human preferences, and integration with external tools and facts. These elements turn raw predictive ability into reliable assistance, shaping LLMs into versatile engines of reasoning, creation, and discovery.
What We Mean by a "Large Language Model"
An LLM is a neural network trained on massive text corpora to predict the next token in context, but in doing so it absorbs patterns of syntax, meaning, discourse, and knowledge. Its “largeness” refers to both scale hundreds of millions to hundreds of billions of parameters and the breadth of data, which together give it the capacity to generalize, hold context, and stay coherent over long spans. The result is a system that can summarize complex documents, generate code tests, translate idioms, design research scaffolds, or explain concepts at varying depths not through magic, but by mapping prompts to likely continuations with enough structure to follow instructions and safeguards to avoid harmful outputs.
How LLMs Represent and Manipulate Language
Text must be converted into numbers through tokenization, which splits it into units often subwords using methods like Byte Pair Encoding (BPE) or unigram models small enough to handle rare words but efficient for sequence length. These tokens become dense embeddings that flow through layers, with the core mechanism being self-attention, which lets the model decide how much each position relates to others (e.g., linking “it” to “the animal”). By stacking many attention and feedforward layers, the model captures dependencies across long text and learns higher-order patterns that shape narrative flow, argument structure, and code logic.
Two other practical concepts matter in day-to-day work:
- •A context window limits how much text a model can process at once; larger windows enable long conversations, full-document reasoning, and codebase refactoring.
- •Decoding controls output diversity: greedy search is repetitive, while nucleus sampling (top-p), temperature, and beam search adjust creativity and quality, with small tweaks shifting responses from bland to inspired or concise to rambling.
Training, Adaptation, and Alignment
Training starts with pretraining on massive, diverse corpora books, articles, web pages, code, transcripts, and curated datasets using the simple objective of next-token prediction, which drives the model to learn grammar, facts, idioms, program structures, and reasoning patterns. This process requires heavy compute with distributed GPUs/TPUs, mixed-precision arithmetic, gradient sharding, checkpointing, and careful scheduling to maximize efficiency and stability. Pretraining produces a model fluent in language but not necessarily reliable in behavior, so further adaptation and alignment are applied to make it follow instructions and respect guardrails.
•Supervised Fine-Tuning:
Teaches instruction following. Curated prompt–response pairs-explanations, step-by-step solutions, and safe refusals-nudge the model to treat prompts as tasks rather than mere prefixes.
•Instruction Tuning:
Widens coverage by exposing the model to many task formats; it learns to treat the instruction itself as a parameter.
•RLHF (Reinforcement Learning from Human Feedback):
Human raters provide preference data used to train a reward model that guides the base model toward preferred outputs, with variants like Direct Preference Optimization offering alternative approaches.
•Parameter-Efficient Tuning (LoRA, Adapters):
Enables domain- or brand-specific specialization without retraining the full model, allowing smaller, customized models to run efficiently on modest hardware.
For factual reliability, systems use retrieval-augmented generation (RAG): querying a vector index for relevant passages before generation, allowing the model to ground answers in sources. This trades some fluency for verifiability, a valuable balance in enterprise use.
Architectures in the LLM Ecosystem
“LLM” is a family name. Several architectures and training recipes coexist, each with a niche:
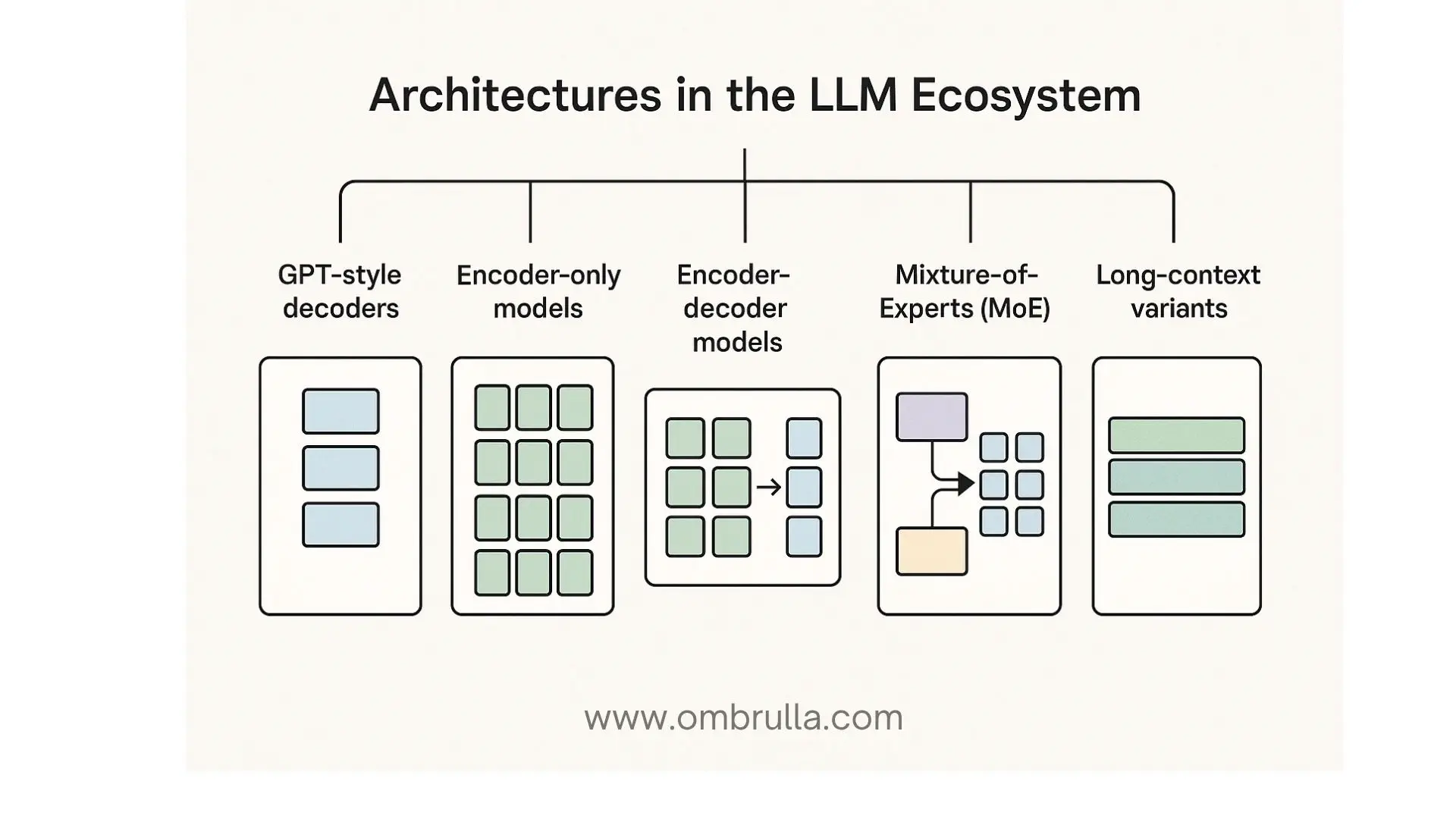
•GPT-style Decoders:
Workhorses of open-ended generation and code. They train on next-token prediction and excel at continuation, rewriting, question answering, tool use via function calling, and few-shot in-context learning.
•Encoder-only Models:
Models like BERT remain indispensable for understanding tasks: classification, retrieval, entity tagging, and as text encoders for cross-modal contrastive learning (e.g., CLIP in vision–language).
•Encoder–Decoder Model:
Models such as T5 treat every task as text-to-text. They shine in translation, summarization, and tasks where input and output have different structures.
•Mixture-of-Experts (MoE):
Architectures route each token through a subset of specialized experts, improving throughput for a given parameter budget. They are increasingly common in systems seeking frontier performance at manageable inference cost.
•Long-context Variants:
Extend the window via attention sparsification, recurrence, or memory tokens, enabling multi-document synthesis, legal reasoning across exhibits, and code assistance at repository scale.
Around these cores sits a maturing stack: PyTorch or TensorFlow for training, DeepSpeed and Megatron-LM for distributed efficiency, Hugging Face for model hosting and standardized APIs, vLLM and TensorRT-LLM for optimized inference, and orchestration frameworks (LangChain, LlamaIndex) to chain models with tools, memories, and retrieval.
What LLMs Actually Do in Practice
LLMs handle first drafts and routine tasks, while humans bring judgment and accountability. They save time, cut busywork, and surface insights but always with checks, citations, and human review.
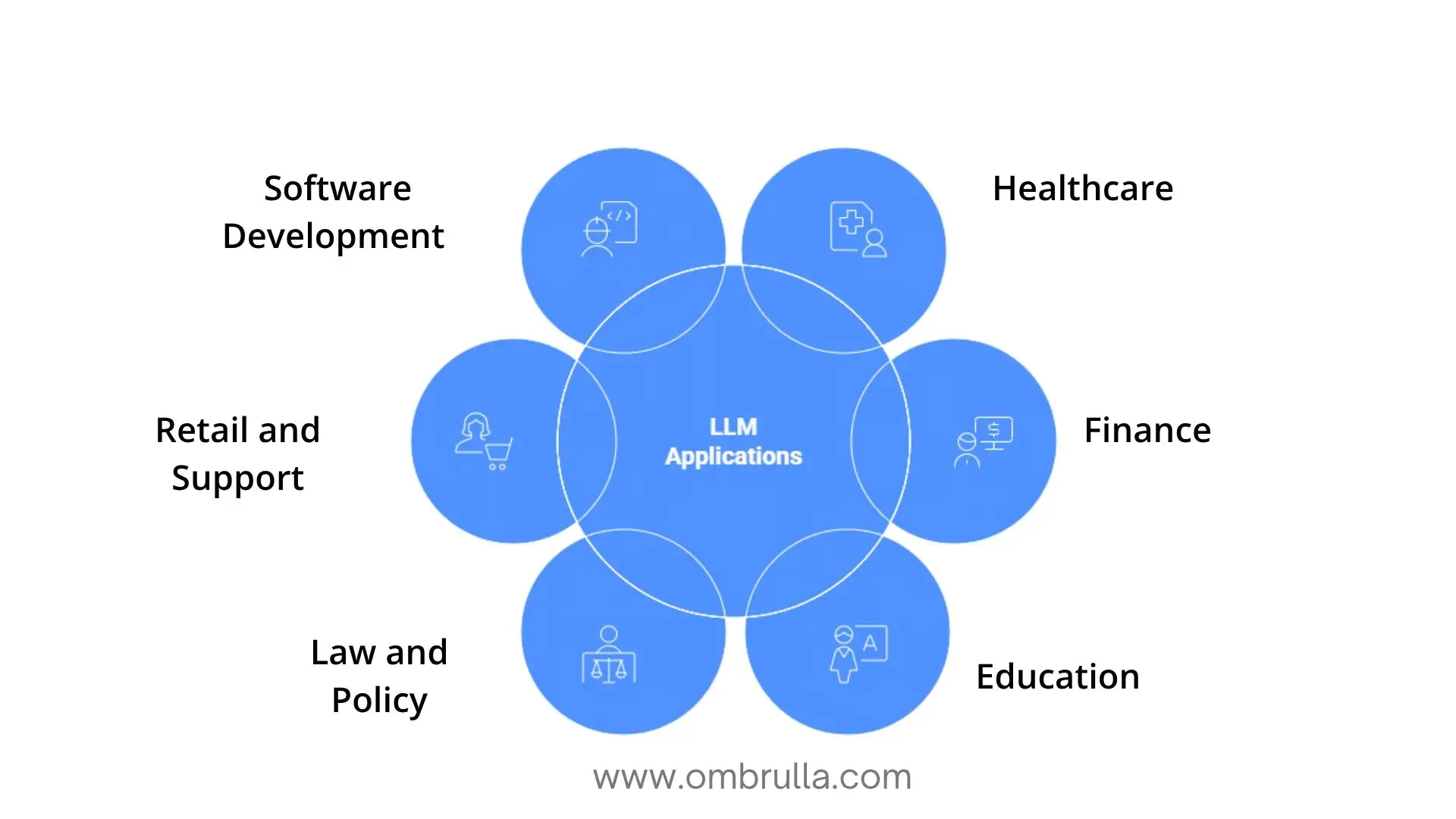
•Healthcare:
LLMs transcribe visits, extract problems and medications, and draft notes for doctors to confirm. In patient portals, they answer routine questions and escalate complex ones. Research teams use them to summarize papers and compare trials, always within safety and privacy boundaries.
•Finance:
Support agents solve issues faster with AI assistance. Compliance teams scan regulations and map changes to policy. Analysts draft earnings summaries linked to filings, and fraud teams describe suspicious patterns clearly-with logging and audit controls in place.
•Education:
Tutors adapt lessons, generate practice problems, and offer feedback on reasoning steps. Teachers create outlines, rubrics, and updates faster. Accessibility improves through translation and plain-language support-while systems are designed to guide, not replace, critical thinking.
•Law and Policy:
LLMs extract clauses, parties, and risks from contracts. They summarize case law, public comments, and policy themes with citations. Outputs are clearly labeled as assistance, not legal advice, preserving accountability.
•Retail and Support:
Models write product descriptions, translate content, and expand specifications into plain language. In customer support, they suggest grounded replies that agents approve before sending. Search improves through semantic matching rather than keyword reliance.
•Software Development:
LLM-based tools autocomplete code, suggest tests, and refactor patterns. They explain errors, scaffold APIs and UI boilerplate, and leverage large context windows to understand entire projects-while final code review remains with developers.
The Limits and the Risks - And How to Manage Them
No technology worth adopting is risk-free. LLMs fail in predictable ways, and robust deployments assume failure and design around it.
•Bias and Representational Harm:
Training data can embed stereotypes and unequal representation. Left unchecked, outputs can replicate or amplify those patterns. Mitigation starts with curated data and continues through evaluation suites that probe for bias, post-processing filters, and explicit safety guidelines for refusals.
•Hallucination:
Models can produce fluent but incorrect statements. Countermeasures include retrieval grounding, citations, calibrated confidence scoring, and human review for critical tasks.
•Security Misuse:
LLMs may be misused to generate exploits, phishing, or fraud content. Preventive steps include adversarial red-teaming, abuse detection, continuous monitoring, and strict policy enforcement.
•Intellectual Property:
Copyright and licensing concerns require transparent sourcing-licensed or public-domain corpora, opt-out mechanisms, and content credentials or watermarks to track provenance.
•Privacy:
Sensitive data must be handled responsibly, using consent-driven collection, redaction, hashing, differential privacy, and strict separation of logs from training data.
•Cost and Carbon:
Training and serving large models are computationally expensive. Efficiency comes from distillation, quantization, mixture-of-experts routing, caching, and choosing smaller models where possible.
•Explainability & Accountability:
Because LLMs are statistical rather than logical, transparency requires structured audits, model cards, rules-based overlays, and traceable data lineage to ensure responsible operation.
Building with LLMs: A Pragmatic Approach
Organizations that succeed with LLMs tend to follow a pattern:
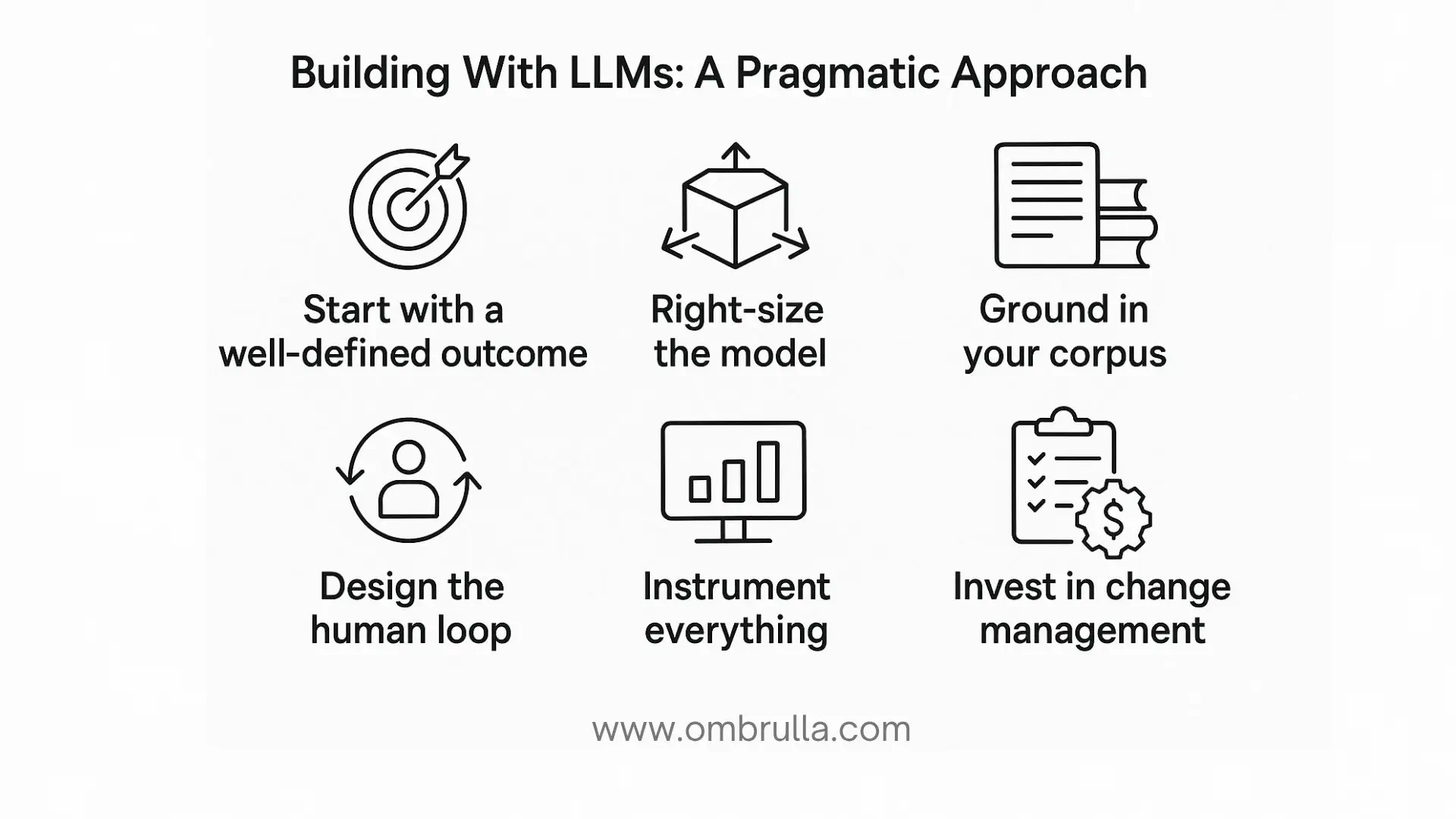
1. Start with a Well-Defined Outcome:
Define measurable goals such as “Reduce average handle time by 25% without lowering CSAT” or “Shorten discharge note drafting by 40% with zero decline in accuracy.” Clear metrics guide system design and evaluation.
2. Right-Size the Model:
Select the smallest capable model, ideally fine-tuned for your domain. Reserve large frontier models for cases that truly need deeper reasoning or broad world knowledge.
3. Ground in Your Corpus:
Anchor outputs in your organization’s data - documentation, policies, code, and prior work. Retrieval-based grounding and required citations reduce hallucinations and ensure relevance.
4. Design the Human Loop:
Determine where the AI proposes and where humans approve. Make uncertainty visible and treat user edits as valuable feedback for continuous improvement.
5. Instrument Everything:
Log prompts and responses responsibly, measure latency and cost, track accuracy and satisfaction, and set alerts for drift in both data and behavior.
6. Invest in Change Management:
AI adoption changes workflows. Train teams, communicate expectations, gather feedback, and iterate. Trust and usability drive success as much as raw technical performance.
Where LLMs Are Heading Next
Trends are already visible, and they are less about novelty than about integration and maturity.
•Multimodality:
Future models will seamlessly process and generate text, images, audio, video, and tables, enabling tasks like annotating a chart in a PDF and getting narrated explanations with spreadsheets or emails in the same session.
•Longer Memory:
Beyond bigger context windows, models will use smarter memory-summarizing past interactions, storing them as embeddings, and retrieving only what’s relevant for continuity without overload.
•Personalization with Privacy:
Fine-tuned adapters on personal documents, styles, and preferences will create tailored experiences while staying local or tenant-specific to preserve confidentiality.
•Efficiency:
Distilled models, sparse routing, and optimized inference on devices will cut costs and latency, with hybrid stacks where local models handle routine tasks and larger hosted ones tackle complex queries.
•Tool Use:
LLMs will evolve into orchestration layers that reliably call APIs, run code, query databases, and schedule jobs-backed by explicit schemas, permissions, and audits.
•Governance:
Model cards, evaluation suites, content credentials, and enforcement policies will be built-in, driven by both platform standards and regulatory expectations.
•Human–AI Collaboration:
Teams will treat collaboration as a craft, developing prompt styles, review checklists, and domain-specific playbooks that shape how AI is applied to maximize outcomes.
Conclusion: Language as an Interface, Judgment as the Differentiator
LLMs are more than “autocomplete on steroids”: they are powerful interfaces that turn intent into structured outputs across domains, speeding iteration and lowering barriers to expert-level work. While they don’t think like humans and can be confidently wrong, grounding, alignment, and careful design make them valuable force multipliers. The greatest gains come not from plugging them into chat boxes, but from clear goals, retrieval, guardrails, measurement, and teaching teams to collaborate with systems that propose rather than dictate. Used responsibly, they remove friction, surface insights, expand expressive power, and amplify human expertise combining machine fluency with human judgment, ethics, and taste.