Future of Bespoke AI Agents: Tools, Planning, and Verification
Abstract
Bespoke AI agents domain-tuned, tool-using systems that can plan, act, and verify are rapidly transitioning from research prototypes to production-grade infrastructure. Building enterprise-grade custom AI solutions requires systematic planning and verification. Unlike traditional chatbots that generate text in a single pass, AI agents function as closed-loop systems: they break down goals, invoke tools and APIs, reason over intermediate steps, and validate outputs against constraints. This shift marks the rise of agentic AI, where systems demonstrate purposeful, multi-step problem solving rather than passive text generation.
This white paper surveys the emerging technology stack for building reliable, scalable, and safe autonomous AI agents. Sophisticated deployments employ multi-agent AI workflows for enterprise automation to orchestrate complex tasks. We outline design patterns, control architectures, and governance requirements needed for production environments. The paper compares leading planning strategies including ReAct, chain-of-thought, program-of-thought, hierarchical controllers, and model-predictive planning and explains when each is most effective within complex workflows powered by agentic AI for industrial operations.
Finally, we detail verification layers essential for trustworthy agent operation, ranging from schema checks and unit tests to learned critics and formal validation pipelines. Implementing explainable AI frameworks for trustworthy enterprise systems improves transparency and auditability. To support engineering and stakeholder communication, the paper includes prompts for diagrams and system illustrations, helping teams design, deploy, and monitor AI agents and autonomous AI agents across real-world applications.
Introduction
AI agents promise to transform work: rather than receiving a single answer, users delegate goals. Designing autonomous AI agents for enterprise operations requires careful planning and verification. (“Prepare a supplier risk brief,” “Draft a remediation plan,” “Summarize Q3 anomalies and open tickets”), and the agent performs a sequence of steps: retrieve facts, run queries, call calculators, reconcile inconsistencies, and produce verifiable artifacts. To deliver reliability at scale, bespoke agents must achieve three properties:
1. Tool competence robust, idempotent tool use with typed contracts, retries, and side‑effect safety.
2. Planning decomposition and routing that balance depth (fewer mistakes) with cost/latency.
3. Verification guardrails and proofs that outputs satisfy schemas, policies, and evidence requirements.
This paper describes a production‑ready architecture, measurement regime, and playbook for organizations building bespoke agents for regulated, high‑stakes domains. Following an enterprise AI transformation roadmap helps teams navigate bespoke agent deployment. For teams seeking custom AI solutions for enterprise workflows, this architecture combines LLM applications, RAG assistants, document automation, edge AI, MLOps, and system integration.
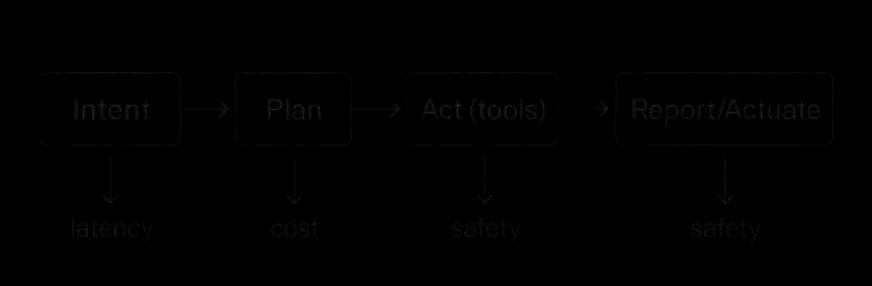
Problem Framing and Requirements
Use‑Case Spectrum
- -Analyst agents: policy research, due diligence, market briefings.
- -Operations agents: ticket triage, escalation, incident write‑ups, workflow automation.
- -Decision agents: vendor screening, anomaly remediation, playbook execution (read‑modify‑write with approvals). Asset performance management workflows capture APM, maintenance planning, asset health, operational risk, and CMMS/EAM integration.
- -Creative/communications agents: brand‑safe messaging, personalized campaigns with guardrails.
Non‑Functional Requirements
Reliability (availability, success rates), quality (rubric scores, factuality), safety (policy compliance, PII/PHI), efficiency (p95 latency, token/calls), auditability (evidence, lineage), cost predictability.
Constraints
Data residency and privacy, rate‑limited upstream systems, heterogeneous corpora, seasonal bursts, multi‑tenant isolation.
Reference Architecture for Bespoke Agents
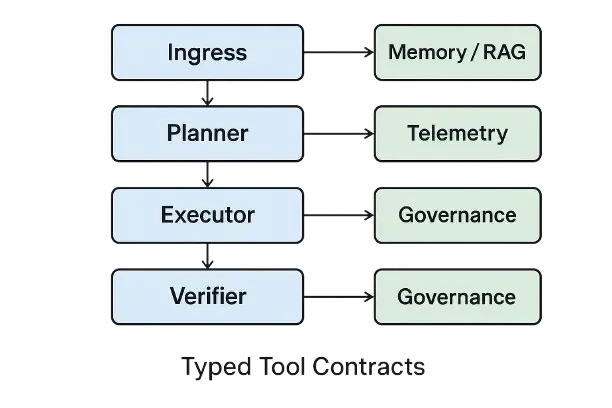
Control and Data Planes
- -Ingress: input validation (schema, size), prompt‑injection defenses, DLP redaction, language/script detection.
- -Planner/Router: selects prompt chain, tools, and model profile based on task and risk tier.
- -Executor: tool calling with typed contracts, retries with backoff, circuit breakers, and idempotency tokens.
- -Verifier/Critic: deterministic validators (schemas, rules, property checks), learned critics (NLI, toxicity, compliance), and evidence verifiers.
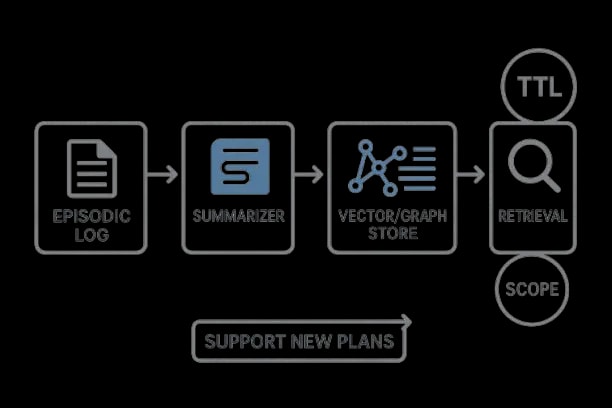
- -Memory/Retrieval: episodic logs, semantic knowledge base/vector store, document graph; cite‑before‑say policies.
- -Observability: traces, cost/latency meters, success/failure taxonomies; error‑budget dashboards.
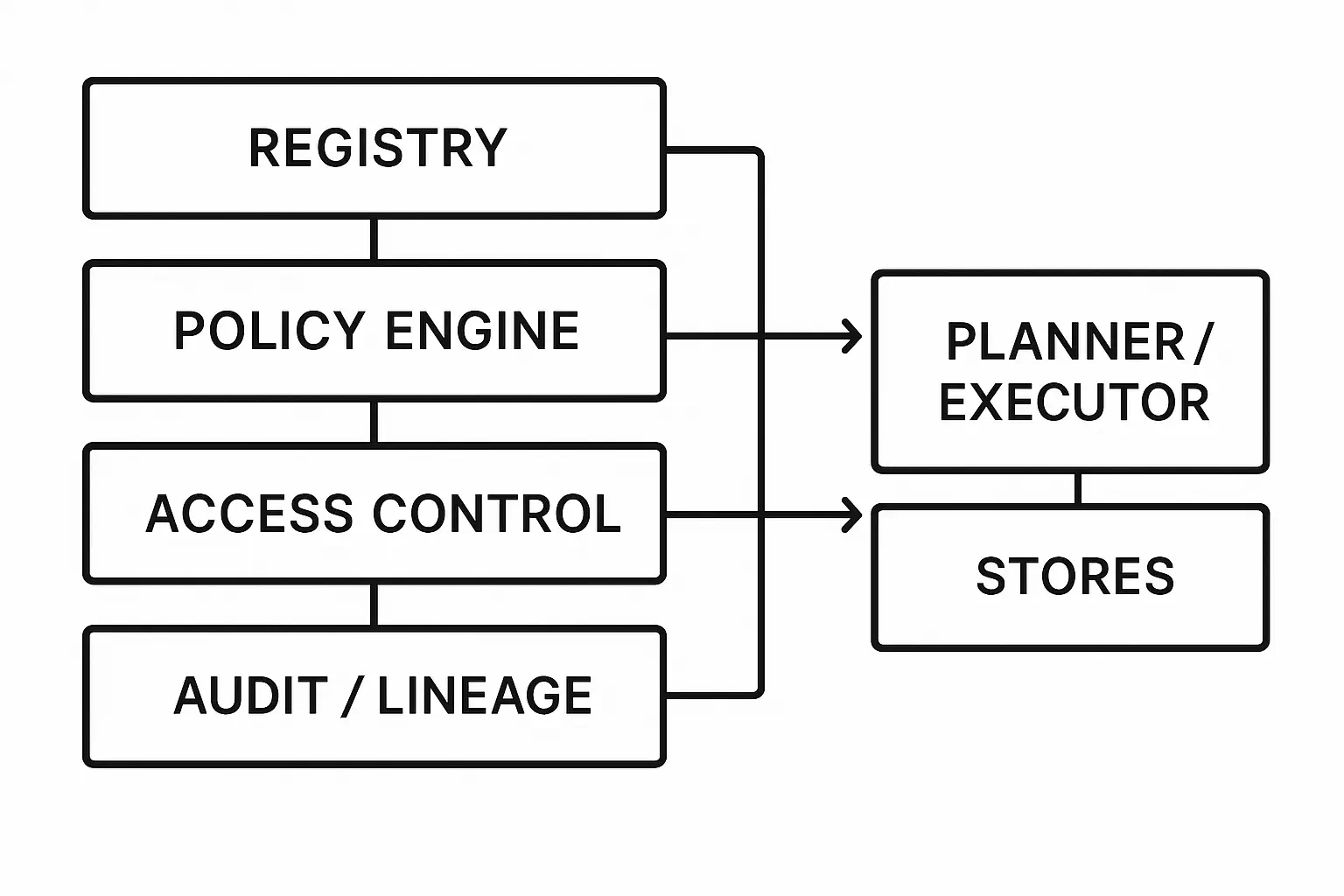
- -Governance: registries (prompts, policies, tools, models), audit/lineage, change control.
Tooling Contracts
- -JSON Schema for arguments/returns; constraints and defaults; examples and counter‑examples.
- -Side‑effect classification: read‑only vs. read‑write; dry‑run modes; preview/confirm steps.
- -Idempotency: request IDs; replay guards; compensating actions.
Data & Evidence Flow
All claims carry evidence tables (source, span, confidence). Leveraging long-context AI systems for enterprise intelligence enables agents to reason over larger contexts. Actions embed preconditions and postconditions tied to evidence.
Planning: From Heuristics to Principled Control
Planning Taxonomy
1. Prompt‑level heuristics: single‑shot with tool suggestions; cheapest but brittle.
2. ReAct (reason + act): interleaved thought/tool steps; good general baseline.
3. Chain/Program‑of‑Thought: explicit intermediate computations; executable sub‑steps with verifiers.
4. Hierarchical planning: task decomposition (planner) and sub‑agents (workers) with supervisors/critics. Multi-agent workflows for vertical AI applications separate planning, execution, review, and governance responsibilities.
5. Model‑Predictive Planning (MPC): rolling horizon re‑planning based on state feedback and cost.
6. Constraint/goal planners: PDDL‑like operators with pre/postconditions; search with heuristics.
Choosing a Strategy
- -Map tasks to risk tiers: Low (heuristics OK), Medium (ReAct+critics), High (hierarchical/MPC + formal checks + HITL).
- -Consider observability: deeper plans improve debuggability via explicit state.
- -Optimize latency/cost with early exit policies and bandit selection among plan templates. Model routing and Mixture-of-Experts for workload-adaptive systems enables planning depth, model profile choice, routing, escalation, and cost control.
Planning Primitives
- -Subgoal generation: “what must be true” statements; each subgoal owns evidence.
- -Routing: to retriever, calculators, structured tools, or human queue.
- -State store: typed World State (facts, timestamps) tracked across steps.
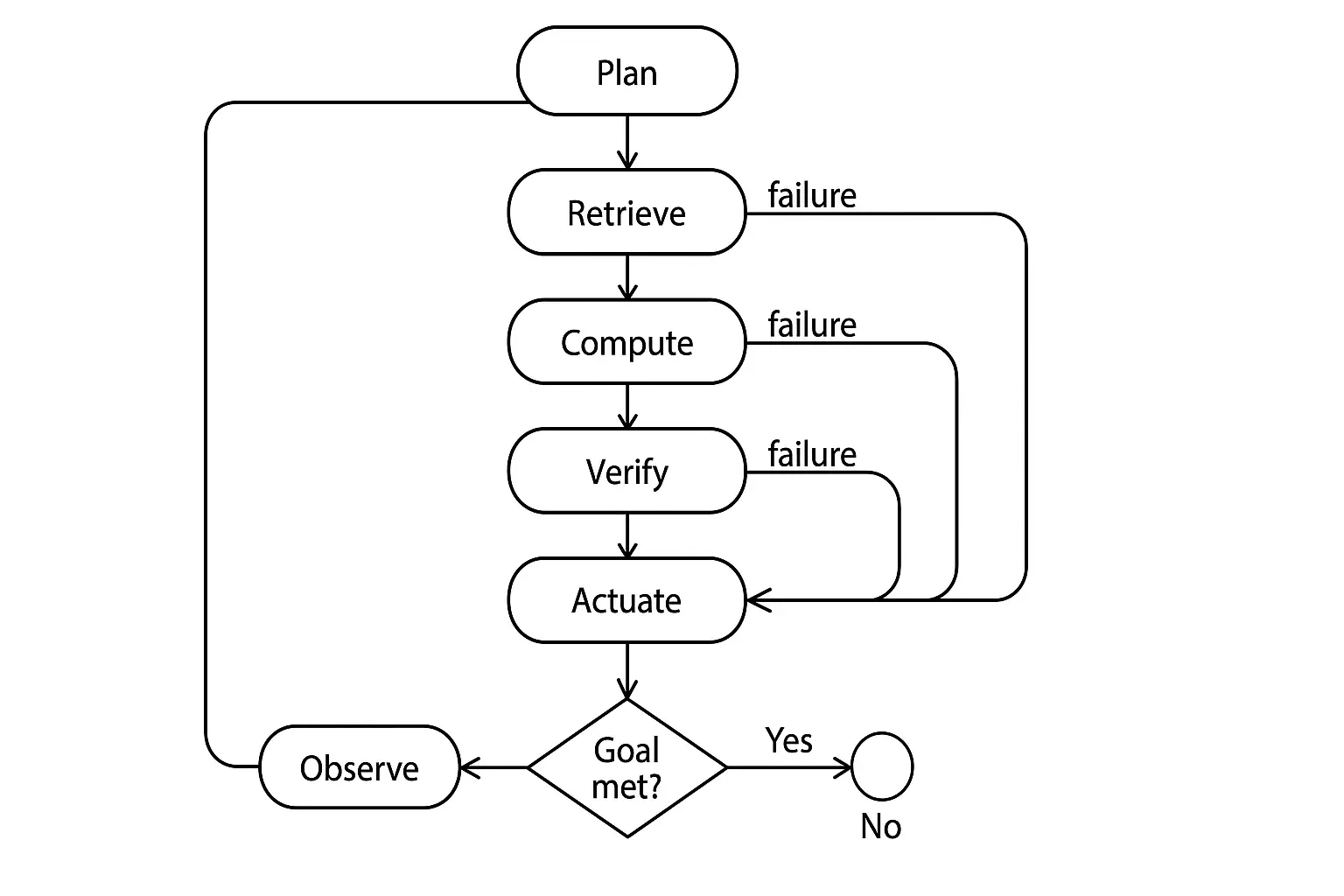
Tools: Design, Discovery, and Safety
Designing Tools
- -Keep single responsibility per tool; declare preconditions/postconditions.
- -Avoid hidden globals; all side effects must be explicit in the signature.
- -Provide sandboxes and dry‑runs for high‑risk actions.
Tool Discovery & Selection
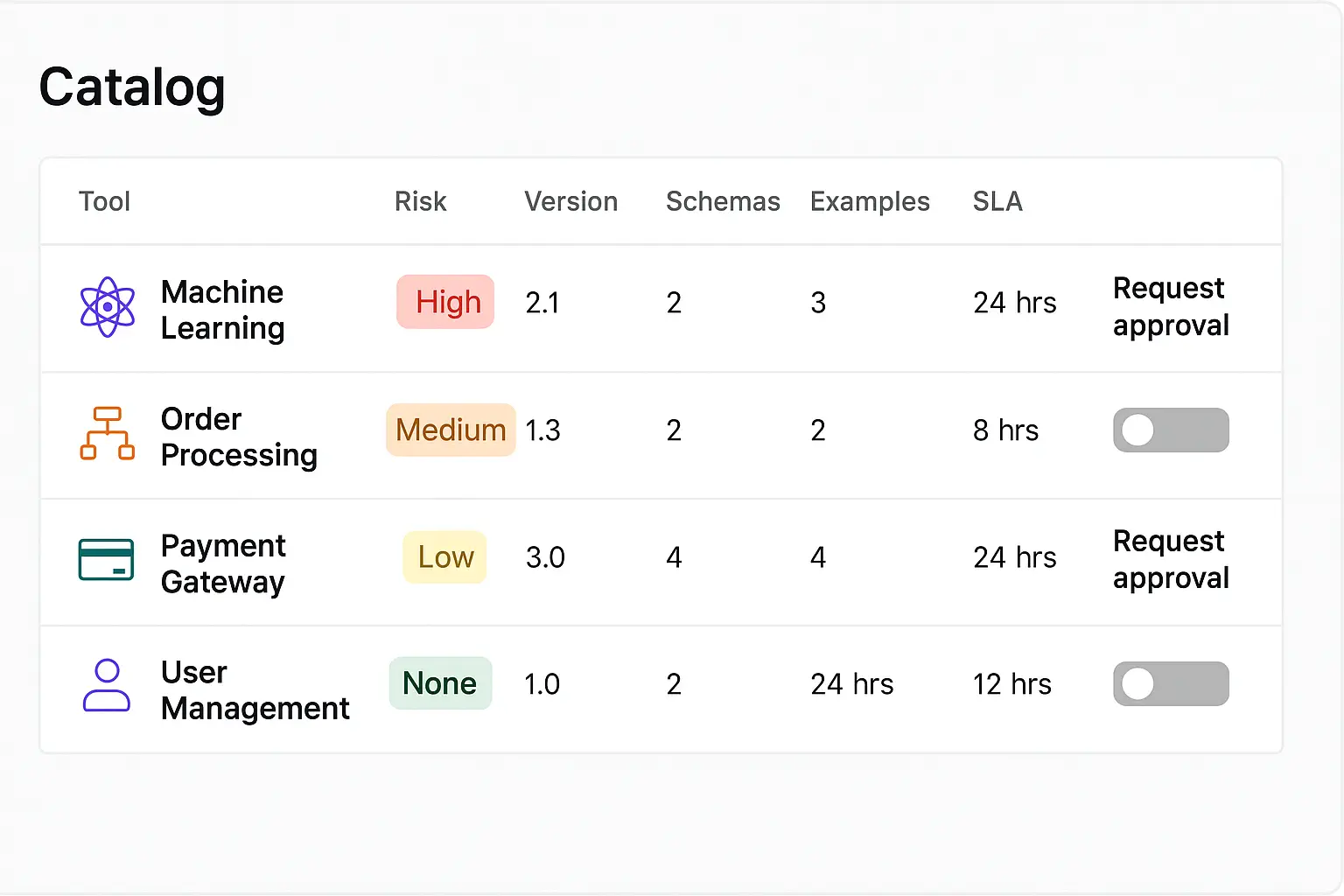
- -Tool registry with metadata (owner, version, risk class, rate limits, SLA).
- -Few‑shot exemplars for correct usage; negative examples for misuses.
- -Learned tool‑chooser classifiers or embedding similarity; fall back to rule‑based allow‑lists for high‑risk actions.
Safety for Tools
- -Capability gating by tenant/risk tier; scope tokens in requests.
- -Quotas and budgets for tokens, steps, money.
- -Transaction review: preview + human approval for irreversible operations.
Verification: Deterministic, Learned, and Formal
Deterministic Checks
- -Schema conformance (JSON, CSV); regex/CFG constraints; type systems for dates, amounts, IDs.
- -Property‑based tests: invariants (sum of parts = total), units and conversion checks.
- -Reference checks: hash‑based proof that cited evidence exists in corpus version v.
Learned Critics and Judges
- -Entailment/NLI for faithfulness; toxicity/PII classifiers; domain compliance models (medical, financial).
- -Self‑consistency and majority vote across diverse decodes for sensitive claims.
- -Critic loops: generator proposes → critic evaluates → generator revises with explanations. Benchmarking custom AI with domain-specific challenge sets scores tool correctness, evidence coverage, policy compliance, cost, latency, and safety metrics.
Formal & Symbolic Methods
- -Pre/postcondition verification for actions; model checking of plan graphs for deadlocks and unsafe sequences.
- -Policy‑as‑code: declarative rules (allow/transform/block) with tests.
HITL and Escalation
- -Risk‑tiered escalation ladders; two‑person rule for irreversible actions; explanatory artifacts (evidence, diffs) for reviewers. Explainable AI for trustworthy agent decisions builds semantic support for trust, transparency, accountability, and regulated AI agent decisions.
Memory, Retrieval, and Grounding
- -Episodic memory for past steps and rationales; semantic memory (vector/graph) for knowledge; working memory for short‑term state. Long-context AI memory architecture connects agent memory, large context windows, retrieval, compression, grounding, and context governance.
- -Hybrid retrieval (BM25 + dense + filters) with reranking; cite‑before‑say enforced; evidence coverage as a first‑class metric. RAG maturity model for production grounding includes retrieval quality, citation coverage, freshness, access control, and hallucination reduction.
- -Privacy scopes and TTLs; right‑to‑erasure workflows.
Observability, SLAs, and Cost Control
Golden Signals + Agent‑Specific SLIs
- -Latency p50/p95/p99 (plan, each tool, verify); success rate; tool error rate.
- -Quality: rubric scores; evidence coverage; faithfulness.
- -Safety: policy violations; leakage; jailbreak resistance.
- -Efficiency: token burn, tool calls, cache hits; cost per accepted artifact.
Error Budgets and Burn‑Rate Alerts
Error budgets for safety and quality; freeze rollouts when burn rates exceed thresholds; switch to evidence‑only or read‑only mode under stress. Event-driven MLOps for continuous customization reinforces AgentOps, LLMOps, monitoring, drift control, rollback, prompt/policy changes, and feedback loops.
Cost Governance
- -Profiles mapping tasks to model sizes; early exits on confidence; budget guards (max steps/tokens/$); degradation paths. Instruction tuning and preference optimization for enterprise agents aligns enterprise AI agents to policies, formats, tone, citations, tool constraints, and safety preferences.
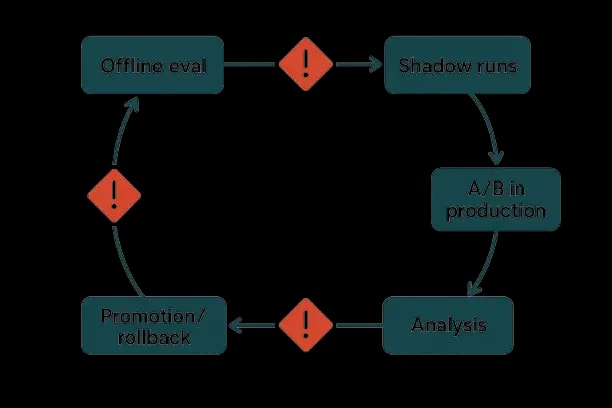
Evaluation and Benchmarks for Agents
Challenge Sets
Goal‑to‑plan tasks with ground‑truth action traces; adversarial prompts; incomplete/conflicting evidence. Rigorous benchmarking custom AI system performance is essential for validating agent improvements.
Metrics
- -Task Success Rate (TSR); Plan Correctness (pre/postconditions satisfied); Tool Correctness; Abstention correctness; Human‑approval rate; Time‑to‑resolution.
Statistical Design
- -Power analyses per cohort; bootstrap CIs; sequential tests for canaries; BH correction across metrics.
Implementation Blueprint
// Typed tool interface
struct ToolSpec { name, args_schema, returns_schema, side_effects, risk_class }
// Planning and execution
function run_agent(goal, ctx):
plan <- planner(goal, ctx) // subgoals + tool calls
state <- {}
for step in plan:
assert preconditions(step, state)
result <- execute(step.tool, step.args)
if !verify(step, result):
result <- revise_or_escalate(step, result)
if result == ESCALATED: break
state <- update(state, result)
report <- synthesize(state, evidence=collect_evidence(state))
if !final_verify(report): return abstain()
return report
function verify(step, result):
return schema_ok(result) && policy_ok(result) && evidence_ok(result)Patterns and Anti‑Patterns
Patterns
- -Cite‑before‑say with refusal paths; typed tools with pre/postconditions; budget guards and capabilities per tenant; prompt/policy registries with diffs and tests; plan depth caps and early exits; HITL for high‑impact actions.
Anti‑Patterns
- -Free‑form tool strings without schemas; implicit side effects; unbounded planning loops; citations as decoration; monolithic prompts; no cohort‑aware metrics; silent prompt/policy changes.
Case Studies: Real‑World Bespoke Agents
Vendor Risk Briefing Agent
-Context:
aggregates contracts, adverse media, sanctions lists; drafts risk memos.
-Approach:
hierarchical planner; RAG with cite‑before‑say; financial calculator tool; NLI critic; human approval for sanctions decisions.
-Outcomes:
TSR +19 pts; violation rate <0.1%; mean time‑to‑brief −32%; p95 cost −27% via plan budget guards.
Ticket Remediation Agent
-Context:
reads monitoring alerts, queries runbooks, proposes and executes fixes. In asset-heavy operations, the same agentic architecture can be implemented through the PETRAN AI and IoT asset performance management platform to turn alerts into governed work orders, evidence trails, and maintenance actions.
-Approach:
MPC planner; dry‑run tools; two‑person rule for writes; rollback plans.
-Outcomes:
MTTR −24%; change‑failure rate −14%; no P1 safety incidents across pilot.
Compliance Filing Assistant
-Context:
prepares regulatory filings using internal ledgers and policies. AI solutions for manufacturing operations creates industry relevance for manufacturing, quality workflows, production alerts, CAPA, 8D, and MES/ERP integration.
-Approach:
program‑of‑thought with spreadsheet and policy tools; formal checks on totals and references; HITL sign‑off.
-Outcomes:
reviewer hours −38%; schema validity 99.8%; zero data residency exceptions.
Security, Privacy, and Governance
- -Registries for prompts, policies, tools, models; signed artifacts and rollbacks.
- -Access control at tool and data layers; regional residency and scoped secrets.
- -Audit: immutable logs; link outputs to evidence and versions; eDiscovery export.
- -Threats: prompt injection via retrieved content; tool misuse; data exfiltration; mitigation via content filters, allow‑lists, and sandboxing. AI predictive maintenance software adds commercial depth for maintenance agents that transform anomalies into RUL estimates, risk scores, work orders, and prioritized interventions.
Economic Model and Capacity Planning
Cost per accepted artifact = (tokens + tool compute + verifiers + human review) ÷ accepted outputs()
Tune model size, plan depth, retrieval k, critic strength to hit ROI; add caches (retrieval, tool results, evidence tables). Edge-cloud co-design for low-latency custom AI supports latency, on-prem, edge runtime, privacy-sensitive processing, verification budgets, and agent SLO discussions.
Model bursts and seasonality; provision for peak with queuing and degradation modes.
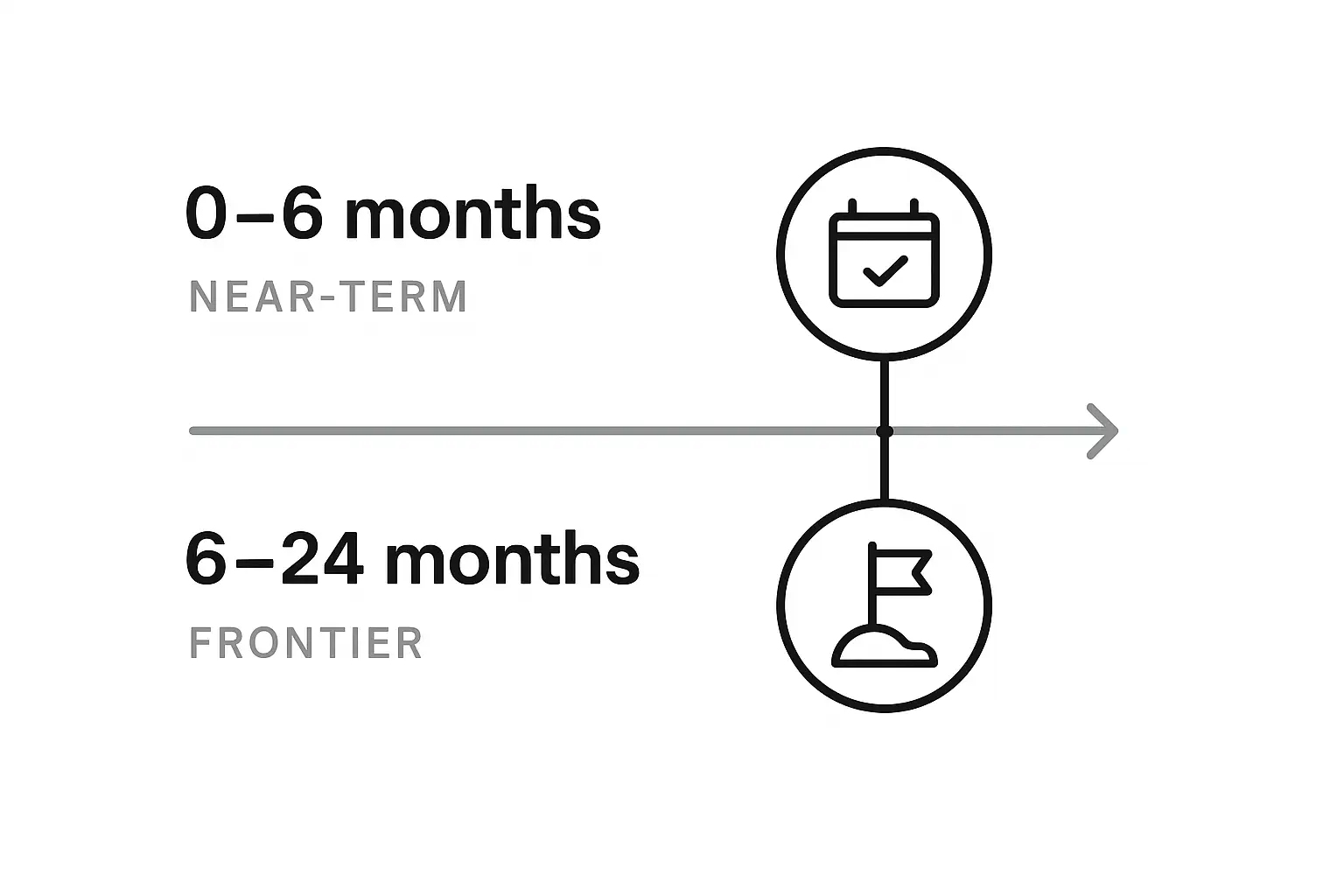
Roadmap: Near Term and Frontier
- -Near‑term: standardized tool schemas; better plan debugging; test libraries; proof‑carrying prompts; stronger entailment critics; cohort‑aware eval suites.
- -Frontier: neuro‑symbolic planners with certified properties; agentic auto‑formalization of subgoals; causal verifiers; privacy‑preserving federated plan learning; executable fact traces. Natural Language Processing in the Transformer Era supports NLP, LLM, transformer, RAG, instruction tuning, safety, and evaluation concepts that underpin agentic AI.
Conclusion
Bespoke AI agents succeed when tools, planning, and verification work as a coherent control system. Typed tools and safe sandboxes enable precise actions. Structured planners backed by evidence and budget guards turn goals into reliable sequences. Verification, from schemas to critics to formal checks and HITL, ensures outputs are not only useful but trustworthy. With robust observability, governance, and cost control, organizations can deploy agentic systems that operate on purpose, at scale, and under audit.
References
- Brown, A., Roman, M., & Devereux, B. (2025). A Systematic Literature Review of Retrieval-Augmented Generation: Techniques, Metrics, and Challenges. arXiv preprint arXiv:2508.06401.[arxiv]
- Liu, X., Wu, Z., Wu, X., Lu, P., Chang, K. W., & Feng, Y. (2024). Are llms capable of data-based statistical and causal reasoning? benchmarking advanced quantitative reasoning with data. arXiv preprint arXiv:2402.17644.[arxiv]
- Yatam, S. N. K. (2025). Infrastructure as Code with Embedded Security Controls: A Policy-as-Code Approach in Multi-Cloud Environments. Journal Of Engineering And Computer Sciences, 4(7), 131-140.[sarcouncil]
- Buccafurri, F., Eiter, T., Gottlob, G., & Leone, N. (1999). Enhancing model checking in verification by AI techniques. Artificial Intelligence, 112(1-2), 57-104.[sciencedirectassets]
- Mohammadi, M., Li, Y., Lo, J., & Yip, W. (2025, August). Evaluation and benchmarking of llm agents: A survey. In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2 (pp. 6129-6139).[dlacmorg]