Instruction Tuning and Preference Optimization for Enterprise Use Cases
Abstract
Enterprise deployments of large language models (LLMs) must satisfy stringent requirements for safety, compliance, latency, cost, and verifiable quality. Building enterprise custom AI solutions requires systematic instruction tuning and preference optimization. While pretrained LLMs exhibit strong general abilities, they are often misaligned with enterprise goals, policies, and formats. This paper presents a comprehensive, IEEE‑style treatment of instruction tuning and preference optimization for enterprise use cases. We formalize objectives and constraints, distinguish data‑centric vs. objective‑centric alignment, and synthesize practical recipes that combine supervised instruction fine‑tuning (SFT), preference modeling (RM), direct preference optimization (DPO‑class methods), and reinforcement learning from human or AI feedback (RLHF/RLAIF). We address data governance, safety and policy alignment, multi‑tenant customization, multilingual and multimodal extensions, and cost/energy considerations. We propose a reference architecture, evaluation protocols that connect offline metrics to online KPIs, and operational playbooks, concluding with open research challenges. NLP transformers methods and evaluation provides foundational context for LLM, transformer, and evaluation concepts. Throughout, we include pseudo‑code and prompts for figures/diagrams suitable for IEEE proceedings.
Introduction
Motivation
Pretrained LLMs are trained on web‑scale corpora with heterogeneous styles and objectives. Following a custom AI development guide for enterprise-grade LLM systems helps teams structure tuning effectively. In enterprises finance, healthcare, manufacturing, energy/utilities, public sector successful deployment requires goal‑conditioned behavior (e.g., policy‑conformant customer replies), schema‑constrained outputs (e.g., JSON for ticket routing), verifiable grounding (citations to internal sources), and predictable costs/latency. General models often deviate from these requirements, motivating alignment via instruction tuning (supervised learning on task instructions and responses) and preference optimization (learning to prefer outputs that better reflect human or policy preferences). For organizations moving from research to production, custom AI solutions combine RAG, fine-tuning, evaluation, governance, and enterprise integration.
Contributions
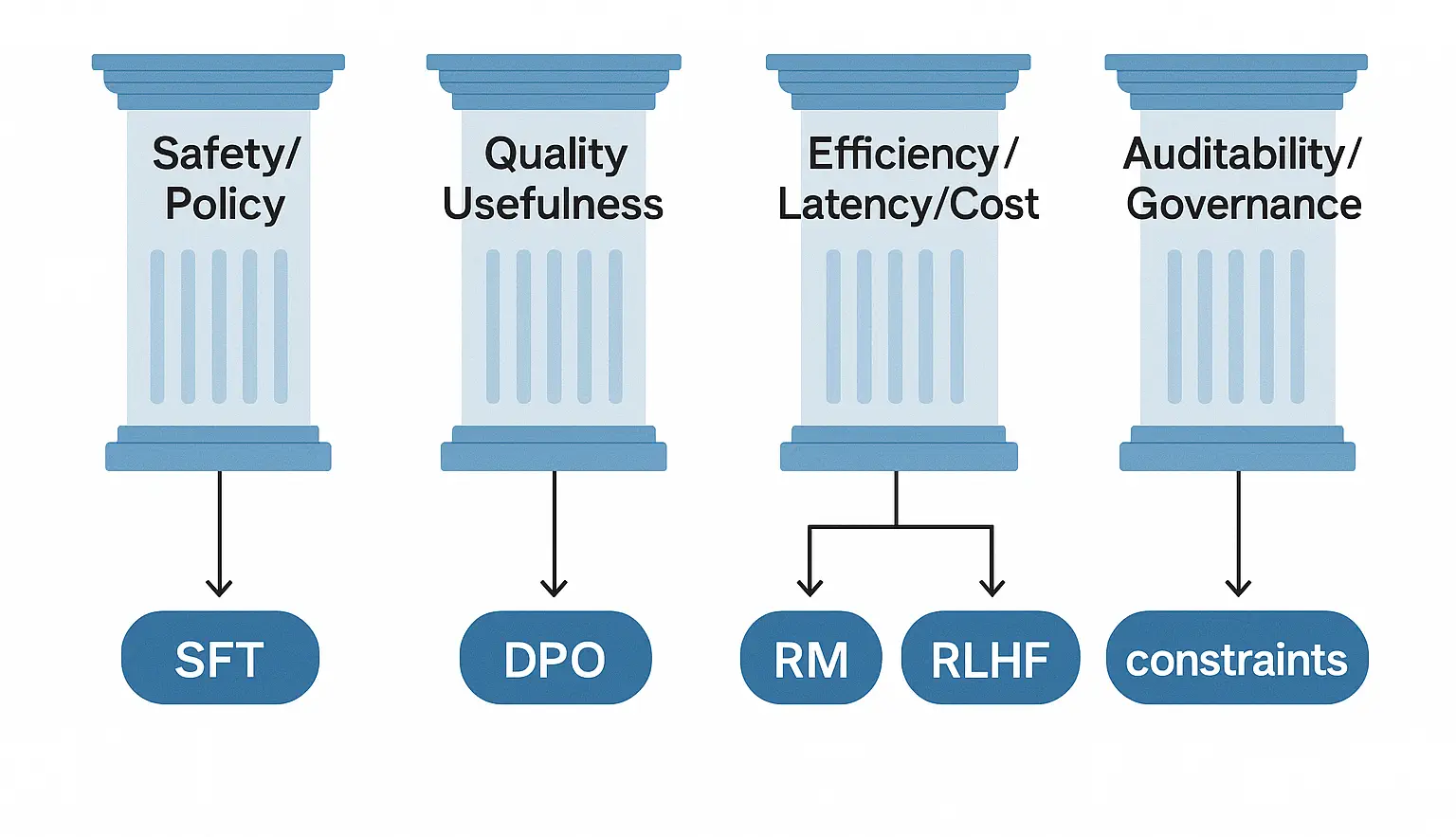
1. A structured taxonomy of alignment methods for enterprises, from SFT to DPO/RLHF with policy constraints;
2. A governance‑aware data pipeline for instruction and preference data;
3. A reference system architecture for multi‑tenant instruction tuning and preference optimization;
4. Evaluation protocols linking offline alignment metrics to online KPIs (safety, faithfulness, TSR/deflection, cost/latency);
5. Implementation blueprints and operational SLOs;
6. Case studies and failure modes.
Scope and Assumptions
We consider text‑centric LLMs with optional tool use and retrieval grounding. We assume enterprise constraints: privacy, residency, auditability, and safety policies. Multilingual and multimodal notes are included where relevant. Future of bespoke AI agents explores tool-using agents, planning, and verification in depth.
Background and Problem Setting
Instruction Tuning
Instruction tuning adapts a pretrained model using pairs ((x, y)) where (x) is an instruction (often with context) and (y) is a desired response. The SFT objective typically maximizes (_i p_(y_i,|,x_i)), optionally with label smoothing, sequence‑level weighting, or curriculum strategies.
Preference Optimization
Preference learning uses comparisons or ratings among candidate outputs for the same input, denoted ((x, y^+, y^-)). A reward model (RM) learns a scalar (r_(x,y)) such that (r_(x, y^+) > r_(x, y^-)). Optimization then shapes (p_(y,|,x)) to place higher probability on preferred outputs under Kullback–Leibler (KL) or other regularization relative to a reference model.
Objective‑ vs. Data‑Centric Alignment
Data‑centric alignment curates high‑quality instruction and demonstration data; objective‑centric alignment shapes the training objective via RMs, DPO‑class objectives, or RLHF with constraints. Effective enterprise alignment blends both.
Enterprise Constraints
Alignment must preserve privacy (PII/PHI), policy compliance, and brand tone; maintain latency/cost budgets; support multi‑tenant preferences; and provide traceability of datasets, prompts, and models.
Enterprise Instruction Tuning (SFT)
Data Specification
Each record contains: instruction, optional context (retrieved passages, tables), system/policy prompt ID, response, metadata (tenant, locale, sensitivity), and evidence table (doc IDs/spans) when grounding is required.
Data Sources
1. Expert‑written exemplars (gold),
2. Harvested enterprise conversations with consent and redaction,
3. Synthetic bootstraps via prompt‑programs with strict filters,
4. Annotator workflows (review/patch/score) with QA.
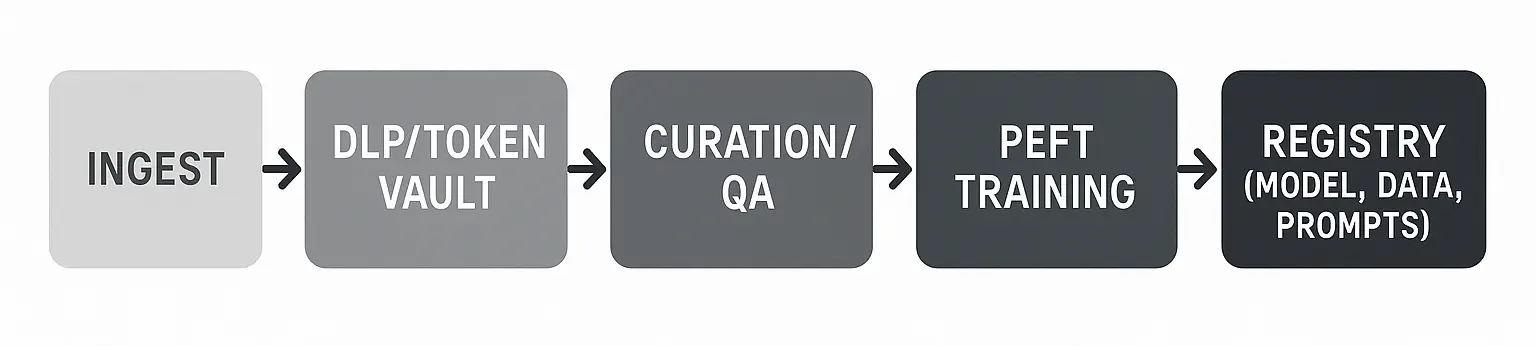
Redaction and Token Vaults
Use DLP at ingest; replace PII/PHI with reversible tokens stored in a vault. Maintain mapping for controlled re‑identification in secured environments.
Curriculum and Weighting
Prioritize high‑impact tasks and safety‑critical examples. Weight samples by recency, risk tier, and cohort coverage. Use difficulty ramps (e.g., short → long context; single‑hop → multi‑hop with tools). Long-context custom AI enables handling of large context windows and complex multi-hop reasoning.
Loss Shaping and Constraints
Apply segment‑wise masking to enforce schema (e.g., JSON fields) and citations (placeholders). Penalize extra‑schema tokens. Add label smoothing for robustness.
Parameter‑Efficient Fine‑Tuning (PEFT)
Favor LoRA/QLoRA adapters per tenant/task to reduce cost and preserve base model. Compose adapters: base‑enterprise + tenant‑specific + locale adapters. When base models are not accurate enough for domain-specific workflows, enterprises can use model fine-tuning and content automation to adapt outputs to their terminology, policies, tone, and structured response formats.
Multilingual Extension
Translate instructions and responses with professional glossaries; ensure locale‑specific policies (e.g., regulated claims) are represented; add code‑switching examples.
SFT Training Loop (Pseudo‑Code)
for batch in dataloader:
x, y, mask, meta = batch
y_hat = model(x)
loss = cross_entropy(y_hat, y, mask=mask)
loss += schema_penalty(y_hat, meta.schema_mask)
loss += citation_penalty(y_hat, meta.citation_slots)
loss.backward(); step()Quality Controls
Require dual review on safety‑critical pairs; deduplicate near‑duplicates; track annotator reliability; embed canary strings to detect leakage.
Preference Data and Reward Modeling
Preference Collection
Use pairwise comparisons with clear rubrics: coverage, correctness, specificity, tone, policy conformance, citations. Adjudicate ties; allow “both bad” labels.
Sources of Feedback
1. Expert raters;
2. End‑user approvals/edits (implicit feedback);
3. AI feedback (RLAIF) via strong critic models for entailment and safety;
4. Online bandit signals (escalation, deflection). RAG maturity model provides guidance on retrieval quality, citation coverage, freshness, and hallucination reduction.
Reward Model (RM)
Train (r_(x,y)) using Bradley–Terry or logistic loss: _{}= -[(r_(x,y^+) - r_(x,y^-)).] Regularize with L2 and anchor to calibration targets (e.g., rubric scores → reward scale). Include policy features (violations negative), citation features, and length penalties.
Calibration
Fit monotonic maps from reward to acceptance probability with human ground truth; maintain per‑cohort calibration. Explainable AI provides transparency, accountability, and trust for enterprise AI decisions.
RM Training (Pseudo‑Code)
for batch in prefs:
x, y_pos, y_neg, feats = batch
r_pos = RM(x, y_pos, feats)
r_neg = RM(x, y_neg, feats)
loss = -log_sigmoid(r_pos - r_neg) + l2(RM)
loss.backward(); step()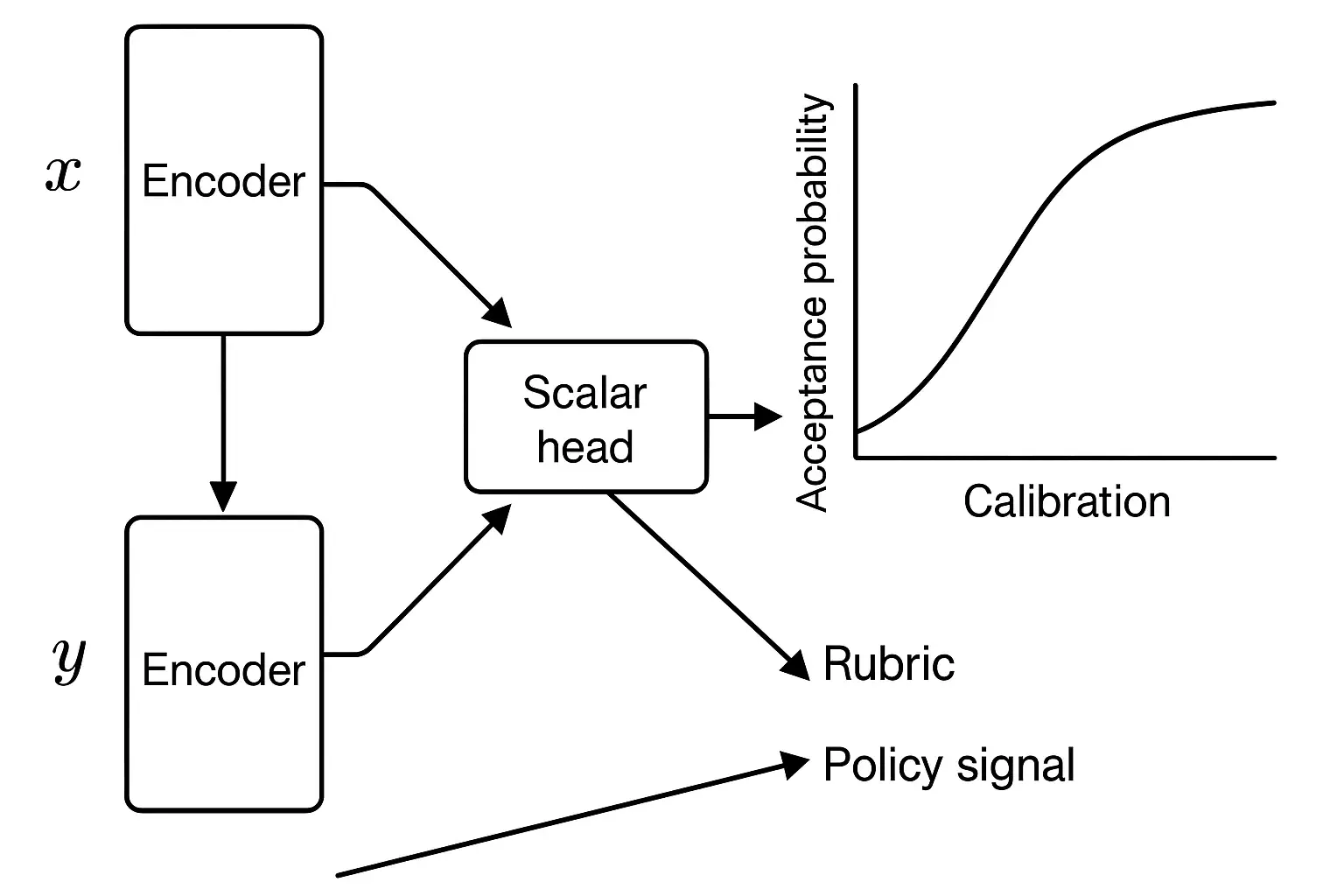
Preference Optimization Objectives
RLHF (KL‑Regularized)
Optimize generation policy (_) to maximize (r_(x,y) - (_,,_)). Proximal policy optimization (PPO) variants are common; enforce constraints on schema and safety via verifiers during rollout.
Direct Preference Optimization (DPO)
Avoid explicit RL by optimizing a closed‑form objective on preference pairs that implicitly matches the optimal KL‑regularized policy. Core loss: _{} = -. Set (_0) as the SFT model; tune () for strength.
Variants and Alternatives
- -IPO (Implicit Preference Optimization): stabilizes gradients using temperature scaling.
- -KTO (Kahneman‑Tversky Optimization): incorporates risk‑sensitive penalties and prospect‑theory‑inspired weighting.
- -ORPO (Odds‑Ratio Preference Optimization): uses odds ratios for better calibration.
- -RLAIF: replace humans with high‑precision critics for large‑scale pretraining of preferences, then fine‑tune with human spot checks. Model routing and mixture-of-experts enables dynamic model selection and cost-aware routing.
Safety‑Aware Preference Shaping
Compose the objective with policy costs: (r’ = r_- _{viol} [] - _{hall} []). Add hard constraints with rejection sampling or constrained decoding.
DPO Training (Pseudo‑Code)
for batch in prefs:
x, y_pos, y_neg = batch
logp_pos = model.logprob(x, y_pos)
logp_neg = model.logprob(x, y_neg)
base_pos = base.logprob(x, y_pos)
base_neg = base.logprob(x, y_neg)
logits = beta*((logp_pos-logp_neg) - (base_pos-base_neg))
loss = -log_sigmoid(logits)
loss.backward(); step()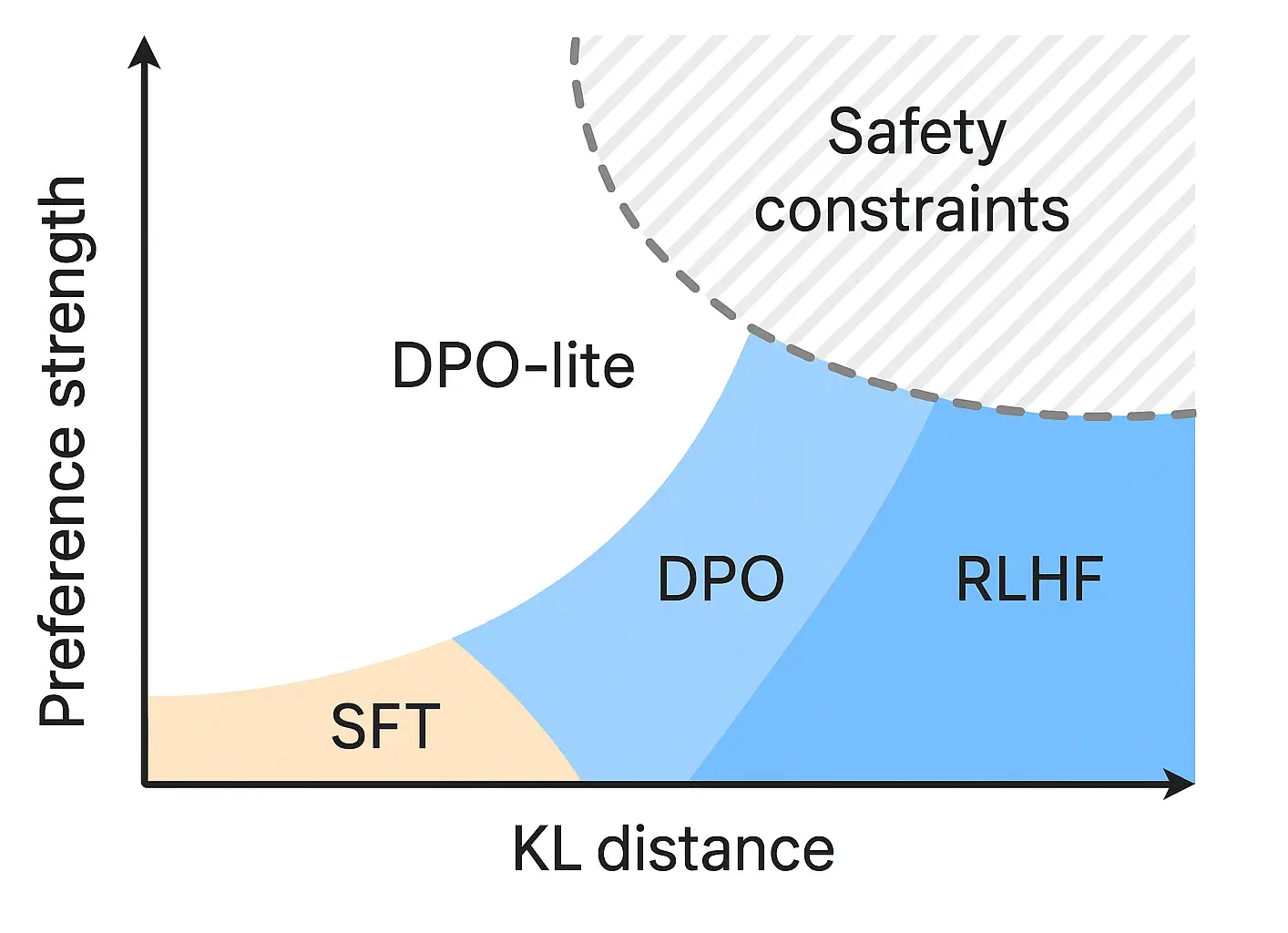
Policy, Safety, and Tool Constraints
Policy‑as‑Code
Encode enterprise policies as declarative rules (allow/transform/block) with test suites; attach policy IDs to datasets and models. Examples: no speculative financial promises, PHI masking, escalation to human for high‑risk advice.
Schema and Determinism
Constrained decoding (regex/CFG/JSON schema) with low temperature for extractors; ensure deterministic formats in evaluations and production.
Retrieval Grounding
Enforce cite‑before‑say; reward citations and entailment; penalize uncited claims. Refuse if no evidence. This is especially important for RAG knowledge assistants grounded in enterprise documents, where every answer should be traceable to approved internal sources.
Tool Use
Guard tools with typed contracts, pre/postconditions, dry‑run previews, two‑person rule for destructive actions; align preferences to prefer safe, previewed actions. These controls are foundational for governed agentic AI for industrial operations, where AI agents must plan, execute, verify, and log actions across business and operational systems.
Multi‑tenant Scoping
Separate adapters and preference heads per tenant; scope caches and reward features; enforce residency and access controls. Secure enterprise AI deployment supports enterprise buyer concerns: security, data residency, RBAC, SSO, audit logs, PII filtering, and compliance.
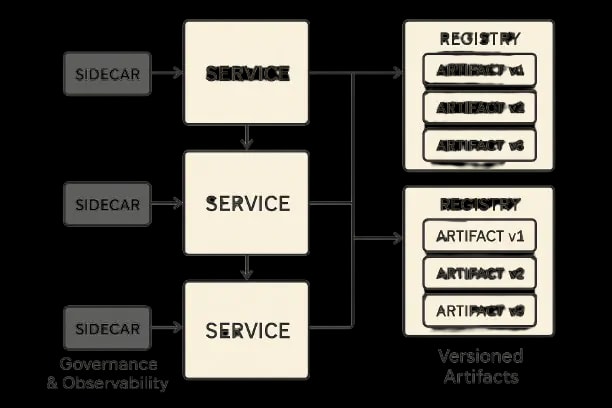
Reference Architecture for Enterprise Alignment
Components
Data ingest & DLP, annotation tools, instruction data lake, preference store, RM trainer, SFT trainer (PEFT), DPO/RLHF trainer, evaluation service (faithfulness, rubric, safety), registry (models/prompts/policies/datasets), governance portal, and deployment orchestrator. Enterprise AI and IoT platform provides integration patterns for connected systems, device-agnostic integration, and autonomous decision engines.
Training Topology
- -Stage 1: SFT adapters per domain/tenant.
- -Stage 2: Preference optimization on shared or tenant data.
- -Stage 3: Safety hardening with adversarial red‑teaming preferences.
- -Stage 4: Online learning via bandit updates (optional). Event-driven MLOps enables continuous customization, monitoring, drift control, and feedback loops.
Deployment Profiles
Define Answer/Summarize/Extract/Agent profiles with decoding, retrieval depth, and policy settings; expose via router. Asset performance management with AI and IoT supports predictive analytics, CMMS/EAM, IoT data, digital twin, and operational monitoring topics.
Observability
Traces with dataset IDs, policy IDs, model and prompt versions; evidence tables; reward scores; safety flags; cost/latency. Production systems also require LLMOps and MLOps so prompts, models, datasets, policies, evaluations, and rollbacks remain traceable over time.
Evaluation: Offline to Online
Offline Metrics
- -SFT quality: exact match (EM)/F1 for extraction; rubric scores for summarization; multilingual BLEU/COMET (when relevant).
- -Preference quality: win rate vs. baseline; reward calibration (Brier/NLL); DPO margin statistics.
- -Safety: policy violation rate on adversarial sets; jailbreak ASR; privacy leakage probes.
- -Faithfulness: citation precision/recall; NLI entailment pass rate.
Robustness and Drift
Test by context length, OCR noise, domain shifts, and multilingual or code‑switching. Before deployment, enterprises should implement AI evaluation, benchmarking, and regression testing to prevent silent quality drift and safety regressions.
Online KPIs
Task Success Rate (TSR), deflection/resolution, reviewer handle time, cost/accepted artifact, latency p95, violation rate, abstention correctness. Track cohort gaps. Edge-cloud co-design addresses latency optimization, on-prem deployment, and privacy-sensitive processing.
Experimentation
Shadow → canary → A/B with CUPED; pre‑registered analysis; hard safety/latency gates; rollback playbooks. Benchmarking custom AI provides comprehensive evaluation frameworks for AI quality assurance and production readiness.
Case Studies
Financial Customer Communications
SFT on policy‑conformant responses; DPO with human preferences for tone and promise control; RLAIF critic for regulatory statements. Multi-agent workflows demonstrate similar patterns for planner, retriever, operator, verifier, and reviewer agent roles. Results: +6.3 pts QA approval, −21% handle time, violation rate <0.1%.
Clinical Summarization
SFT with de‑identified EHR snippets; DPO weighting coverage and entailment; hard refusal on missing evidence. AI visual inspection for quality control demonstrates similar patterns for defect detection, structured inspection outputs, quality reports, and audit records. Results: hallucinations −78%, reviewer time −34%, stable latency.
Manufacturing Quality Reports
SFT on templates; DPO to prefer concise, structured outputs; tool gating for workflow actions. In visual quality workflows, aligned LLMs can convert inspection outputs from an AI visual inspection and defect detection platform into structured quality reports, CAPA summaries, and audit-ready records. Results: JSON validity 99.7%, p95 latency ≤ 3.8 s, cost/accepted −25%.
Implementation Blueprints
Data & Governance Schema
Each dataset/log carries: dataset_id, purpose, policy_id, tenant, jurisdiction, sensitivity, license, retention, version_hash.
Training Schedules
SFT → DPO → safety hardening (adversarial preferences) on weekly cadence; adapters per tenant; freezing base. AI infrastructure inspection demonstrates similar modular architecture patterns for multi-modal AI systems.
Resource & Cost
Prefer PEFT and quantized inference; cache prefixes; cap retrieval depth; DPO often cheaper than full RLHF; RLAIF for pre‑screening. Predictive maintenance AI for industrial assets demonstrates latency, cost reduction, ROI, and industrial deployment outcomes.
Pseudo‑Code: End‑to‑End Alignment
# Stage 1: SFT
M_sft = peft_train(M_base, SFT_data)
# Stage 2: Reward model (optional)
RM = train_reward_model(Pref_pairs)
# Stage 3: DPO or RLHF
if use_DPO:
M_aligned = dpo_train(M_sft, Pref_pairs)
else:
M_aligned = rlhf_train(M_sft, RM, rollouts, verifiers)
# Stage 4: Safety & Red-team hardening
M_aligned = adversarial_dpo(M_aligned, safety_pairs)
# Registry & deployment
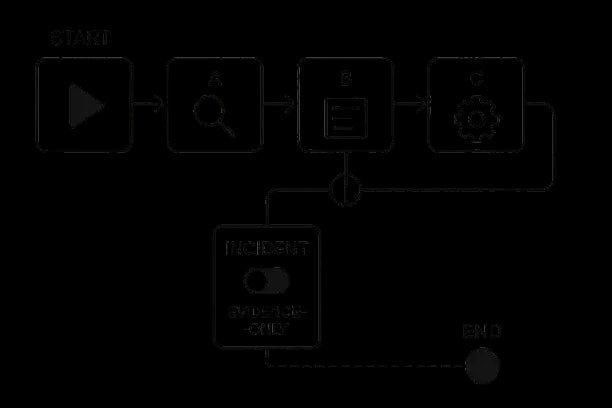
register(M_aligned, datasets, policies, prompts)Runtime Controls
Enforce schema/regex; evidence‑only mode for incidents; abstain on low entailment confidence. For operational deployment and industrial AI workflows, the AI asset performance management platform connects aligned LLMs to real-time monitoring, predictive maintenance, work orders, evidence, and audit trails.
Risks, Anti‑Patterns, and Mitigations
Over‑optimization to Reviewers
Narrow rubrics can induce unwanted styles. Mitigation: rotate reviewers, multi‑objective preferences, audit drift. Vision-language models extend alignment to multimodal scenarios with image reasoning and visual question answering.
Safety Regressions via Preference Shifts
Use composite rewards and hard constraints; add negative examples; maintain red‑team suites.
Data Leakage & IP
Enforce DLP/token vaults; dedupe by content hashing; rights management and licensing.
Cohort Harm
Track fairness deltas by language/region/tenant; add counterfactual preferences; HitL for sensitive cohorts. Energy and utilities asset intelligence demonstrates edge ML deployment for utilities, substations, and grid resilience.
Poor Generalization
Ensure coverage of long tail; curriculum learning; synthetic diversity checked by human spot reviews. Manufacturing AI predictive quality demonstrates similar evaluation patterns for production lines and quality workflows.
Cost/Latency Creep
Budget guards; profile routing; quantization; retrieval caps; caching. IoT real-time monitoring provides operational alerts, telemetry, thresholds, and anomaly detection for industrial deployments.
Related Work
Instruction tuning at scale; RLHF for dialogue safety and helpfulness; direct preference optimization families; RLAIF; constrained decoding and programmatic control; policy‑as‑code and auditability; enterprise deployments and evaluation methodologies.
Open Challenges
1. Formal guarantees for safety‑constrained preference optimization;
2. Multi‑objective alignment (safety, faithfulness, tone, brevity) with tunable trade‑offs per tenant;
3. Continual alignment under data drift and seasonal preferences;
4. Cross‑lingual preference transfer;
5. Agent/tool alignment with verifiable pre/postconditions. One practical direction is combining aligned LLMs with an industrial digital twin with agentic AI workflow orchestration, allowing enterprises to simulate decisions before executing actions in the physical environment;
6. Energy/carbon‑aware alignment training and inference.
Conclusion
Instruction tuning and preference optimization are complementary strategies for aligning LLMs to enterprise objectives. By combining PEFT‑based SFT with calibrated preference optimization (DPO/RLHF/RLAIF), strict policy constraints, and rigorous evaluation connected to KPIs, organizations can realize reliable, safe, and cost‑effective AI systems. The architectures, datasets, objectives, and operational playbooks outlined here provide a replicable path from prototype to production at audit‑ready scale. If your enterprise is evaluating instruction tuning, RAG, preference optimization, or agentic AI, you can explore enterprise AI solutions to validate business impact before scaling.
References
- Wei, J., Bosma, M., Zhao, V. Y., Guu, K., Yu, A. W., Lester, B., ... & Le, Q. V. (2021). Finetuned language models are zero-shot learners. arXiv preprint arXiv:2109.01652.[arXiv]
- Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., ... & Lowe, R. (2022). Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35, 27730-27744.[neurips]
- Bai, Y., Kadavath, S., Kundu, S., Askell, A., Kernion, J., Jones, A., ... & Kaplan, J. (2022). Constitutional ai: Harmlessness from ai feedback. arXiv preprint arXiv:2212.08073.[ai-plans]
- Rafailov, R., Sharma, A., Mitchell, E., Manning, C. D., Ermon, S., & Finn, C. (2023). Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36, 53728-53741.[neurips]
- Sullivan, R. (2025). Applying Policy Gradient Methods to Open-Ended Domains (Doctoral dissertation, University of Maryland, College Park).[proquest]