The RAG Maturity Model: Stages, Metrics, and Anti‑Patterns
Abstract
Retrieval‑Augmented Generation (RAG) has emerged as the dominant architecture for grounding large language model (LLM) outputs in enterprise knowledge. Advanced systems leverage long-context AI architectures for enterprise knowledge retrieval to handle larger document collections. Yet most deployments evolve ad hoc: teams bolt on vector search, tweak chunk sizes, and add caches without a coherent roadmap. This white paper proposes a RAG Maturity Model (RMM) a staged framework for capability building, evaluation, and governance. We define six stages (RMM‑0 through RMM‑5), each with architectural patterns, operational practices, required controls, and exit criteria. We present quantitative metrics spanning retrieval quality, answer quality, efficiency, safety, and reliability, and catalog common anti‑patterns and failure modes with mitigations. We include prompts for diagrams, dashboards, and architecture visuals, and finish with implementation checklists and case studies.
Introduction
RAG systems combine retrievers (keyword, dense, hybrid) with generators (LLMs) to answer questions, perform extraction, or synthesize documents using citations from a knowledge corpus. Building enterprise-grade custom AI solutions requires careful attention to retrieval quality and generation reliability. Effective RAG requires more than embeddings and a prompt: content freshness, chunking strategy, query reformulation, reranking, evidence attribution, evaluation, and governance determine real‑world outcomes. Without deliberate maturation, organizations ship brittle demos that regress under volume, multi‑tenant complexity, or adversarial inputs.
This paper introduces the RAG Maturity Model (RMM) a structured path from prototype to production at scale. Implementing explainable AI frameworks for trustworthy enterprise systems ensures transparency in retrieval and generation decisions. Each stage includes architectural guidance, people/process prerequisites, and measurable gates to progress. We also map anti‑patterns to stages, helping teams recognize and correct systemic issues early.

RAG Fundamentals
Core Components
- -Corpus Ingest: connectors, parsers (PDF, HTML, Office), OCR, normalization, deduplication.
- -Indexing: chunking, embeddings, keyword inverted index, graph construction, metadata tagging, versioning.
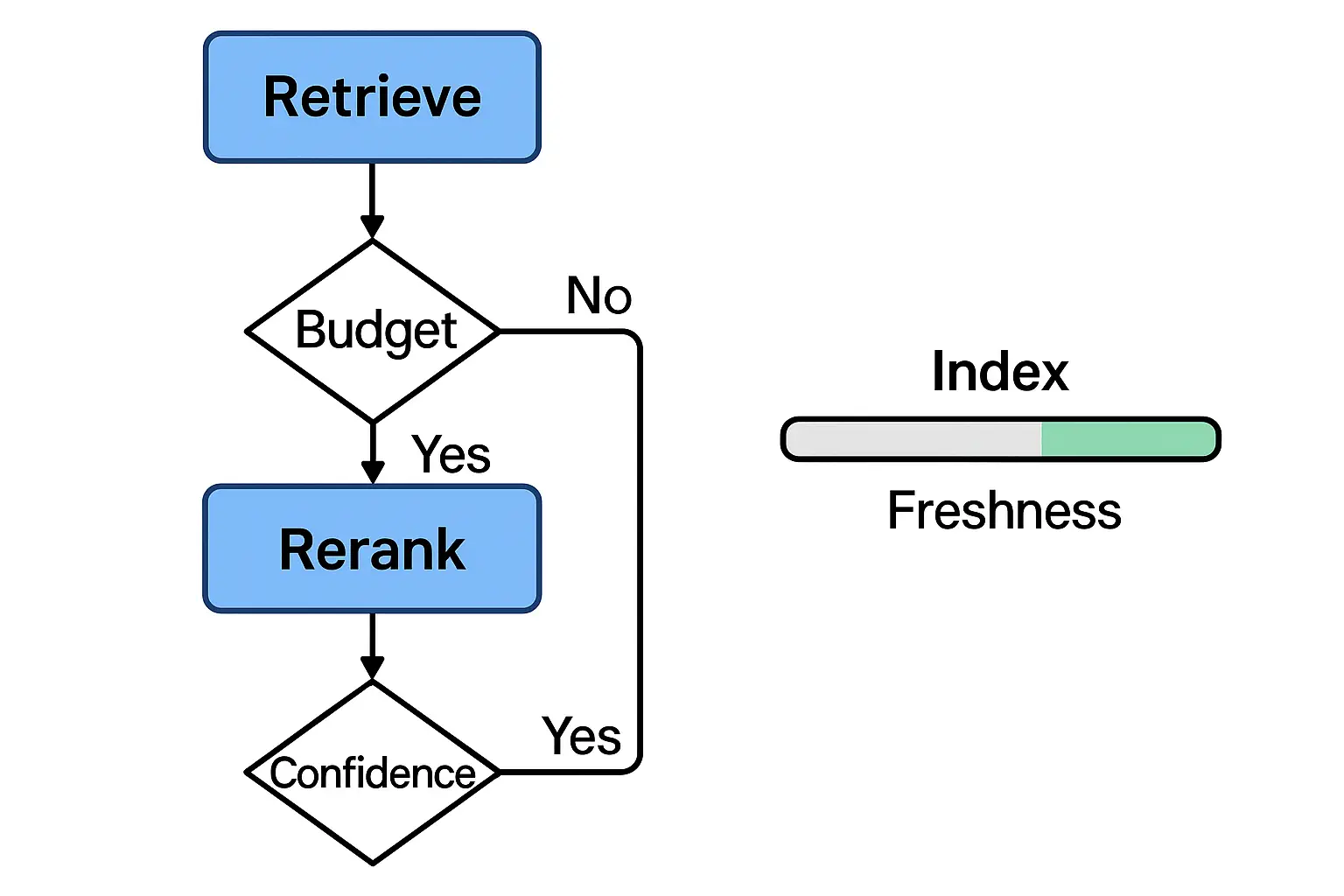
- -Retrieval: ANN vector search, BM25/keyword, hybrid fusion, query rewrite, multi‑hop expansion, reranking.
- -Generation: prompts with cite‑before‑say constraints, tool/function calls, templates.
- -Attribution: evidence tables, source identifiers, snippet alignment.
- -Observability: traces, retrieval logs, ranking diagnostics, cost/latency meters.
- -Governance: content lifecycle, access controls, data residency, audit, redaction.
The RAG Maturity Model (RMM)
We define six stages. Advancement requires meeting exit criteria across architecture, metrics, and governance. Rigorous benchmarking custom AI system performance is essential for validating RAG system improvements.
RMM‑0: Exploration (Ad‑Hoc Demo)
Characteristics - Single corpus snapshot; manual uploads. - Naïve chunking (fixed 512–1k tokens); single embedding model. - Single retriever; direct LLM synthesis; no citations enforced. - Minimal metrics; manual spot checks.
Risks - Hallucinations; stale content; leakage in logs; unpredictable cost.
Exit criteria - Basic evidence table with clickable citations. - Corpus and index are clearly defined assets with version tags.
RMM‑1: Structured Prototype
Architecture - Automated ingest jobs; normalized metadata (source, author, timestamp, ACLs). - Hybrid retrieval (BM25 + vector) with OR fusion. - Prompt templates with cite‑before‑say; top‑k evidence table.
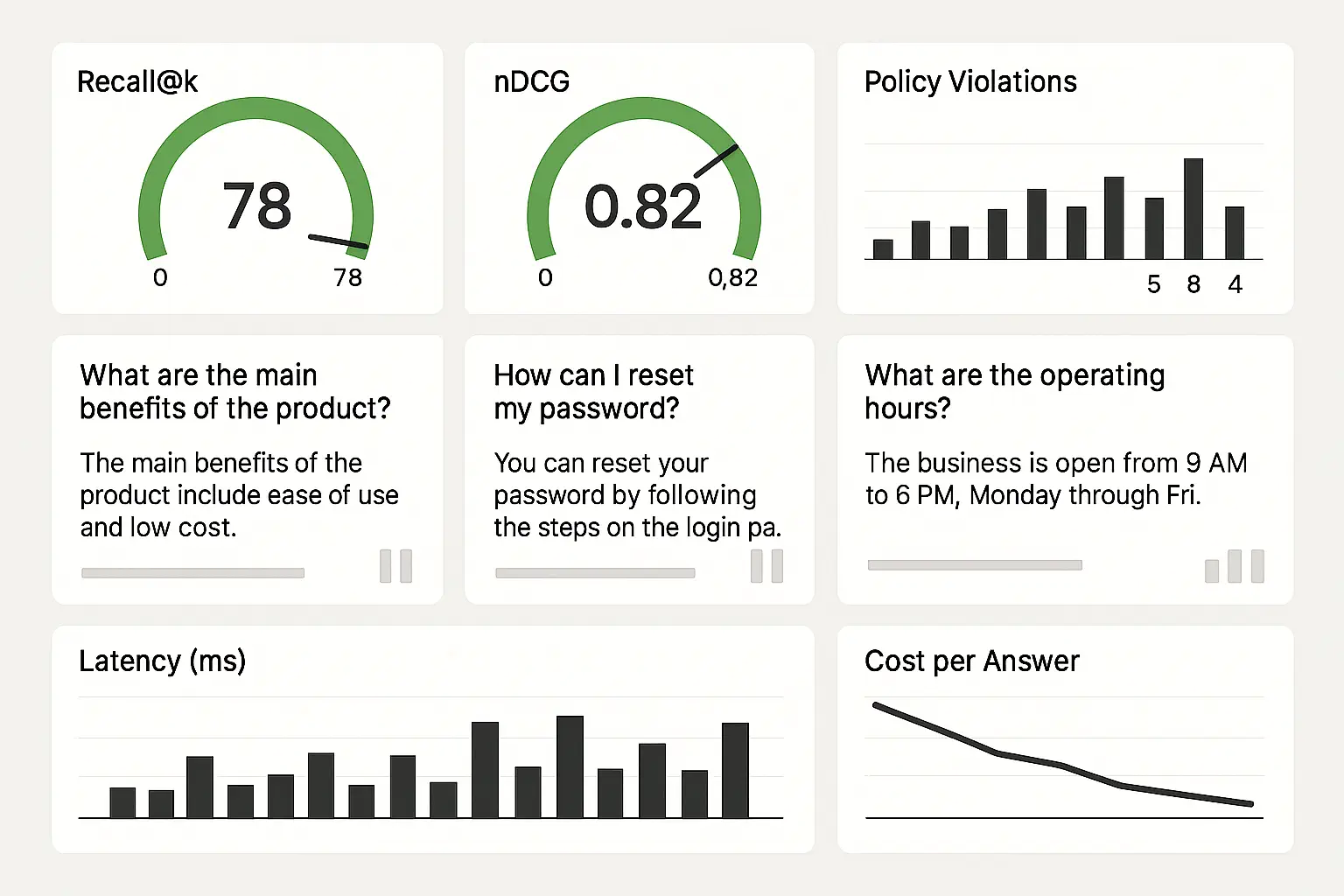
Operations - Offline evaluation set (1–2k queries) with relevance labels. - Dashboards for Recall@k, nDCG, answer grading samples.
Controls - Access control by tenant and collection; redaction at ingest; log masking.
Metrics/Gates - Recall@20 ≥ baseline X; nDCG@10 ≥ Y; hallucination rate < Z% in sample.
RMM‑2: Production Pilot
Architecture - Query reformulation (self‑querying or multi‑query) and reranking (cross‑encoder) before generation. - Structured prompts with output schemas; function/tool calls for post‑processing. - Freshness: incremental indexing; SLA on indexing lag.
Operations - Canary tests; cohort‑aware metrics (by source type, document age, language). - Burn‑rate alerts on error budgets for latency and failure rates.
Controls - PII/PHI detectors; policy guardrails; rate limits; per‑tenant cost budgets.
Metrics/Gates - nDCG@10 uplift ≥ +10% vs. RMM‑1; exact‑match/ROUGE/LFQA rubric scores improved with 95% CI; p95 latency ≤ threshold.
RMM‑3: Scaled Production
Architecture - Multi‑collection routing; hierarchical retrieval (section → doc → KB) and multi‑hop expansion. - Learning‑to‑rank (LTR) or distillation‑based rerankers. - Caching layers (query/result/document); feature store for retrieval signals. - Automated prompt library with versioning; prompt linting tests.
Operations - Continuous relevance labeling via HITL with disagreement sampling. - SLA‑backed SLOs for availability, p95 latency, evidence coverage, cost; per‑cohort reporting.
Controls - Model/prompt registry with signed artifacts; audit trails; DLP on logs; red team probes.
Metrics/Gates - Answer acceptance rate ≥ target; evidence coverage ≥ 98%; monthly regression debt < 2% (percentage of queries degraded vs. last release).
RMM‑4: Knowledge‑Infused Reasoning
Architecture - Integration with knowledge graphs (KG) and table stores; join reasoning across graph edges. - Program‑of‑Thought or tool‑augmented reasoning; SQL/graph queries. - Multi‑step agents constrained by state machines; critics verifying citations.
Operations - KG freshness and consistency checks; entity disambiguation SLIs. - A/B testing for query planning strategies.
Controls - Policy enforcement on write actions; high‑confidence thresholds required for autonomous actions; HITL for high‑risk steps.
Metrics/Gates - Complex question answering (multi‑hop) F1 ≥ target; table‑join accuracy; KG alignment score.
RMM‑5: Adaptive & Self‑Optimizing RAG
Architecture - Bandit‑driven retrieval policy selection (keyword/vector/graph/multi‑query). - Auto‑index maintenance: chunking and embedding refresh guided by drift and usage. - Personalized retrieval with privacy‑preserving profiles.
Operations - Continuous training for retrievers/rerankers from click/approval signals; safe online learning protocols.
Controls - Guarded exploration; rollback on metric regression; privacy budgets.
Metrics/Gates - Online reward uplift vs. fixed policy; stable or reduced cost per accepted answer.
Metrics and Evaluation
Retrieval Metrics
- -Recall@k (strict/lenient), nDCG@k, MMR diversity, Overlap@k across strategies, Coverage by collection and time.
- -Freshness: index staleness distribution; lag percentiles.
Answer‑Quality Metrics
- -Exact Match and F1 for extractive QA.
- -Citation Precision/Recall (cite‑before‑say adherence; evidence coverage ratio).
- -Rubric‑based grading (coverage, correctness, specificity) with inter‑rater κ.
- -Faithfulness via automated checks (e.g., entailment or claim verification heuristics).
Efficiency & Reliability
- -Latency p50/p95/p99 (retrieve, rerank, generate); throughput; cache hit rates; token burn.
- -Availability and error rates per component.
Safety & Compliance
- -Policy violation rate; PII/PHI leakage; jailbreak resilience.
Business Metrics
- -Task Success Rate (TSR); analyst time saved; case throughput; resolution quality; cost per accepted answer.
Anti‑Patterns and Failure Modes
1. Chunk Soup: arbitrarily sized chunks; no boundaries; leads to noisy retrieval. Fix: semantic chunking with structural cues; overlapping windows tuned per doc type.
2. Vector‑Only Myopia: ignoring keyword/metadata. Fix: hybrid retrieval with BM25, filters, and fusion.
3. Static Embeddings Forever: never refreshing embeddings after schema/prompt changes. Fix: index rebuild policies; embedding drift monitors.
4. Prompt Rot: unversioned prompts evolving in notebooks. Fix: prompt registry, tests, and diffs.
5. Evidence as Decoration: citations not enforced; hallucinations sneak in. Fix: cite‑before‑say templates; refusal without evidence; critic checks.
6. Over‑reranking Latency: cross‑encoders everywhere. Fix: cascade reranking; early exits; budget guards.
7. Cache Blindness: no cache or wrong TTLs. Fix: stratified caches (query, doc, snippet) with invalidation.
8. No Cohorts: aggregate metrics hide failures. Fix: cohort‑aware dashboards (doc type, age, language, OCR quality).
9. Index Lag Neglect: stale indexes during peak updates. Fix: incremental pipelines; backpressure; freshness SLIs.
10. Access Control Gaps: retrieval leaks across tenants. Fix: row‑level ACLs at index time; query‑time filters; audits.
11. Unbounded Costs: long contexts, too many hops. Fix: token budgets, step caps, MAB for policy selection.
12. Eval Once, Ship Forever: no post‑deploy monitoring. Fix: continuous eval; shadow tests; red‑team probes.
Architecture Patterns by Stage
- -RMM‑1: Hybrid OR fusion, top‑k 20, strict cite‑before‑say, simple reranker.
- -RMM‑2: Multi‑query reformulation, cross‑encoder reranker, schema‑bound generation.
- -RMM‑3: LTR reranking, hierarchical indexes, result caching, prompt registry.
- -RMM‑4: KG + table joins, tool‑augmented reasoning, critics, plan‑exec graphs.
- -RMM‑5: Bandits for policy; auto‑index tuning; personalization with privacy.
Evaluation Design
Datasets
- -Construct golden sets by domain; include updated and obsolete versions of documents; mark OCR noise; add adversarial queries.
- -Label relevance at passage level and answer spans; capture worker rationales.
Protocols
- -Offline: compute retrieval and answer metrics; bootstrap CIs.
- -Online: interleave A/B with shadow traffic; collect implicit signals (clicks, time‑to‑first‑citation) and explicit ratings.
Statistical Methods
- -Sequential testing with α‑spending; power analysis for expected uplifts; cohort‑aware comparisons; BH correction for multiple metrics.
Governance, Security, and Compliance
- -Access control at index and query time; tenant isolation; content filtering.
- -PII/PHI redaction at ingest; log masking; eDiscovery exports.
- -Model & prompt registries with signed artifacts; audit trails; rollback plans.
- -Change control for indexes and prompts; maintenance windows.
- -Risk reviews (model risk tiers); red‑teaming; incident response runbooks.
Implementation Blueprint
struct Query { text, user_ctx, filters, k }
struct Passage { id, text, source, ts, score }
struct Evidence { passage_id, span, score }
function rag(query):
q1 <- rewrite(query)
cand <- retrieve_hybrid(q1, k=100)
reranked <- cascade_rerank(cand) // BM25 -> bi-encoder -> cross-encoder
top <- select_top(reranked, k=8)
answer <- generate_with_citations(top, policy=cite_before_say)
if low_confidence(answer) or missing_citations(answer):
return refuse_or_escalate()
return answer
function incremental_index(doc):
chunks <- semantic_chunk(doc)
meta <- extract_metadata(doc)
embed <- embedding_model(chunks)
upsert_index(chunks, embed, meta)
log_freshness(doc.id, now())Operational Playbook
SLAs/SLOs
- -Indexing Lag: 95% ≤ 15 min; Freshness Coverage: ≥ 95% queries answered from ≤ 24h content.
- -Evidence Coverage: ≥ 98% claims with citations; Faithfulness: ≥ 95% by automated checks.
- -Latency: p95 end‑to‑end ≤ 4 s; Cost: p95 ≤ budget.
On‑Call & Incident Response
Severity matrix (P1: outage or leakage; P2: retrieval collapse; P3: latency regressions). Organizations building autonomous AI agents for enterprise operations often use RAG as a foundational component. Runbooks for index lag, embedding drift, retriever outage, reranker overload, generator rate limits.
Degradation Modes
Evidence‑only mode (no synthesis); Read‑only actions; Small‑model fallback; Reduced k with stricter filters. Combining RAG with predictive analytics for enterprise intelligence enables more sophisticated knowledge-grounded forecasting.
Case Studies
Legal Knowledge Assistant
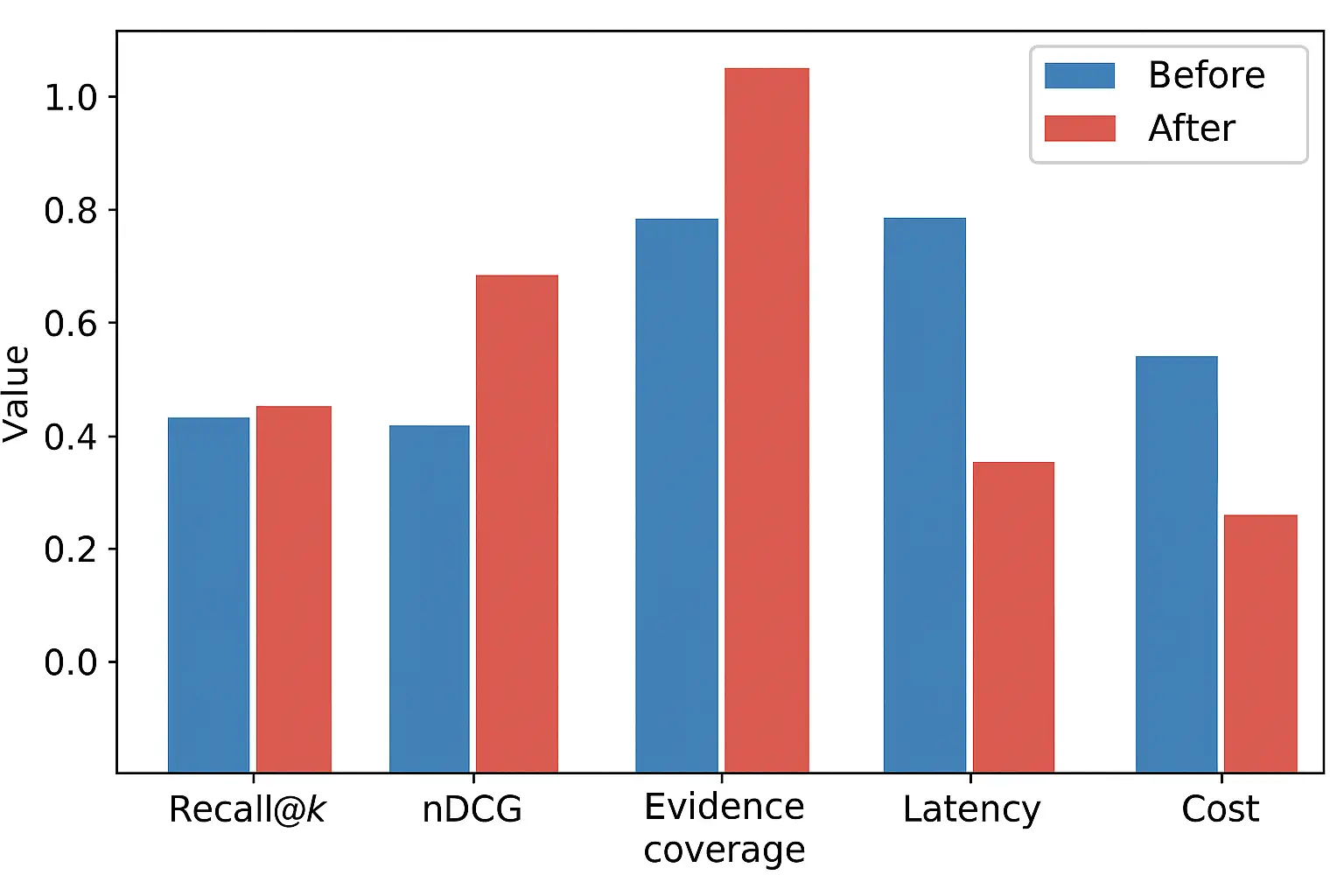
RMM‑1 → RMM‑3 in 10 weeks; nDCG@10 +18 pts; evidence coverage from 72% → 99%; operator trust improved; cost per answer −35% via caching and cascade re. This organization employed multi-agent AI workflows for enterprise automation to orchestrate retrieval and generation tasks.ranking.
Customer Support Copilot
Introduced multi‑query + LTR; solved brand guideline adherence via prompt registry and critics; reduced average handle time (AHT) by 24%; deflection u. Following an enterprise AI transformation roadmap helped this team navigate RAG deployment at scale.p 15%.
Engineering Search across RFCs and Code
Added code‑aware chunking and graph hops (imports); improved Recall@50 by 22 pts; latency p95 kept < 3.8 s with aggressive caches.
Checklists
Stage Advancement Checklist
- -Golden set with relevance and answer labels.
- -Hybrid retrieval and reranking in place.
- -Cite‑before‑say enforced with refusal.
- -Freshness SLIs and index lag monitors.
- -Prompt registry and signed artifacts.
- -Cohort‑aware dashboards.
Launch Readiness
- -Canary and rollback runbooks rehearsed.
- -Cost and latency budgets enforced via guards.
- -Red team probes and jailbreak tests.
- -eDiscovery export validated.
Future Directions
- -Tool‑augmented RAG for structured queries (SQL/KG) and calculators.
- -Continual learning from operator feedback with privacy.
- -Federated RAG for cross‑tenant learning without sharing raw data.
- -Explainable rerankers with feature attributions.
Conclusion
RAG’s promise grounded, controllable, useful answers materializes only when teams invest in disciplined retrieval, evaluation, and governance. The RAG Maturity Model provides a shared map for product, engineering, and risk teams to navigate the journey from demo to dependable system. By progressing through stages with clear gates and by avoiding known anti‑patterns, organizations can deliver faster, safer, and cheaper results with high operator and customer trust.
References
- Gao, Y., Xiong, Y., Gao, X., Jia, K., Pan, J., Bi, Y., ... & Wang, H. (2023). Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997, 2(1).[baai.ac.cn]
- Hu, Y., & Lu, Y. (2024). Rag and rau: A survey on retrieval-augmented language model in natural language processing. arXiv preprint arXiv:2404.19543.[arxiv]
- Brown, A., Roman, M., & Devereux, B. (2025). A Systematic Literature Review of Retrieval-Augmented Generation: Techniques, Metrics, and Challenges. arXiv preprint arXiv:2508.06401.[arxiv]
- Es, S., James, J., Anke, L. E., & Schockaert, S. (2024, March). Ragas: Automated evaluation of retrieval augmented generation. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations (pp. 150-158).[aclanthology]
- Shao, Z., Gong, Y., Shen, Y., Huang, M., Duan, N., & Chen, W. (2023). Enhancing retrieval-augmented large language models with iterative retrieval-generation synergy. arXiv preprint arXiv:2305.15294.[arxiv]