When Machines See and Speak: A Comprehensive Research Paper on Vision–Language Models
Abstract
Custom AI solutions for enterprise intelligence like Vision–Language Models (VLMs) are what you get when you stop treating computer vision and NLP like two separate departments and force them to work the same shift. One model sees an image (or a video frame), reads text (a prompt, a work instruction, a question), and learns to connect them. Not just “identify a bolt,” but “identify the bolt and answer whether it’s missing, misaligned, or acceptable given today’s spec.”
That matters in industry. Especially anywhere you’re running AI visual inspection systems for industrial automation, AI defect detection, or automated AI quality control. In a factory, the model doesn’t get points for a clever caption. It gets points for being right, repeatable, and boring in the best possible way.
This paper gives a structured, research-first overview of VLMs for technical practitioners and researchers. We lay out the core problem and what “alignment” actually means in practical terms. We break down major architectural families dual encoders versus fusion models and what that implies for speed, accuracy, and deployability. We also cover the learning approaches that dominate the field (contrastive, generative, masked, hybrid; pretraining and fine-tuning) and how evaluation is typically done across captioning, VQA, retrieval, reasoning, and multimodal alignment.
Then we get into the part most papers politely skip: deployment reality. Bias, hallucination, privacy, interpretability, compute cost, latency. In the lab, those are footnotes. On a production line, they’re the difference between rollout and rollback. We close with governance implications and the research directions that actually matter for industrial teams: edge-optimized models, stronger multimodal reasoning, better few/zero-shot behavior, broader modality support, and agent-like systems that can interact with real processes. The paper also includes figure prompts to help teams communicate architectures and workflows useful when you need an auditable story for an AI quality control pipeline, not just another diagram that looks good in a slide deck.
Finally, we explore practical deployment considerations, real-world applications, and major challenges including bias, hallucination, privacy, interpretability, compute efficiency, and latency. We highlight governance needs and outline future research directions, such as edge-optimized models, stronger multimodal reasoning, improved few/zero-shot performance, expansion beyond image–text modalities, and agentic interactive systems. The paper concludes with figure prompts designed to help teams communicate system architectures and workflows, especially relevant for AI quality control pipelines that require clear, auditable visual reasoning processes.
Introduction
AI systems that can both see and speak are changing how machines interact with the world and yes, that includes the factory floor. A Vision–Language Model takes visual input (images; increasingly video) and text input (questions, prompts, instructions), and learns to link the two. The goal isn’t “vision + language” as two parallel outputs. The goal is connection: the system should understand what the instruction refers to in the image, and respond in a way that stays grounded in what’s actually there.
That grounding piece is where things get interesting and where things go wrong. A VLM should be able to answer questions about an image, describe a scene, retrieve relevant visuals from a text query (and vice versa), or follow instructions that point to specific visual elements. That’s the promise.
In practice, VLMs have moved fast from research demos to building blocks inside multimodal search, accessibility tools, content understanding systems, and “assistants” that can look at what you’re looking at. The acceleration isn’t magic. It’s a convergence of four pretty concrete forces:
- -Transformers that scale well for both vision and language.
- -Large image–text corpora (messy, imperfect, but huge).
- -Self-supervised and weakly supervised objectives that don’t require hand-labeling every detail.
- -Fine-tuning and instruction-tuning that can turn a general model into something task-shaped and interactive.

Here’s my opinion, after watching industrial AI projects stumble for years: the real breakthrough wasn’t that models learned to “see.” It’s that they learned to map language onto visual evidence well enough that people started trusting them for more than tagging photos. Explainable AI for transparent multimodal systems is essential for building this trust. Trust is the currency here.
Contributions
This paper reframes a practitioner summary into a research-oriented overview that:
- -Formalizes the VLM problem setting and taxonomy, so we can stop using “multimodal” as a vague compliment.
- -Surveys architectures and learning paradigms, with attention to what they imply for real use cases.
- -Consolidates evaluation practices, datasets, and metrics commonly used across captioning, VQA, retrieval, reasoning, and alignment.
- -Discusses deployment patterns, including where teams typically get burned (latency, drift, compute budgets).
- -Analyzes limitations, risks, and ethics, because industrial adoption doesn’t happen without governance.
- -Identifies future directions aligned with emerging practice edge-ready VLMs, stronger reasoning, improved few/zero-shot performance, modality expansion beyond image–text, and interactive agentic systems that can operate inside real workflows.
If you’re building for AI defect detection or AI visual inspection, the bar isn’t “state of the art.” The bar is “works every day, under ugly conditions, without surprising anyone.” Generative AI systems and multimodal intelligence must meet this practical standard. This paper is written with that bar in mind.
Problem Formulation and Scope
Let 𝓘 denote an image (or a short video clip represented as sampled frames) and Ta sequence of tokens representing text (a prompt, question, or instruction). A VLM learns mappings:
- -𝑓𝑉 : 𝓘 ↦ 𝑣 for visual features (via a vision encoder),
- -𝑓𝑇 : 𝑇 ↦ 𝑡 for textual features (via a language encoder/decoder), and
- -optionally, 𝑔:(𝑣,𝑡) ↦ 𝑧 for fused or aligned multimodal representations.
Depending on the architecture, the model may output: (i) retrieval scores in a shared embedding space (dual-encoder contrastive models), (ii) text sequences (captions, answers, rationales) conditioned on visual tokens (fusion models with cross-attention), or (iii) both, in hybrid designs. The task family includes captioning, VQA, cross-modal retrieval, and visual reasoning, together with instruction-following behaviors that reference the visual context.
Scope: We focus on image–text models while acknowledging increasing interest in video–text and richer multimodality (audio, sensor data). We assume transformer-based implementations for both modalities and concentrate on the design choices that most influence capability and efficiency.
Related Work and Model Families
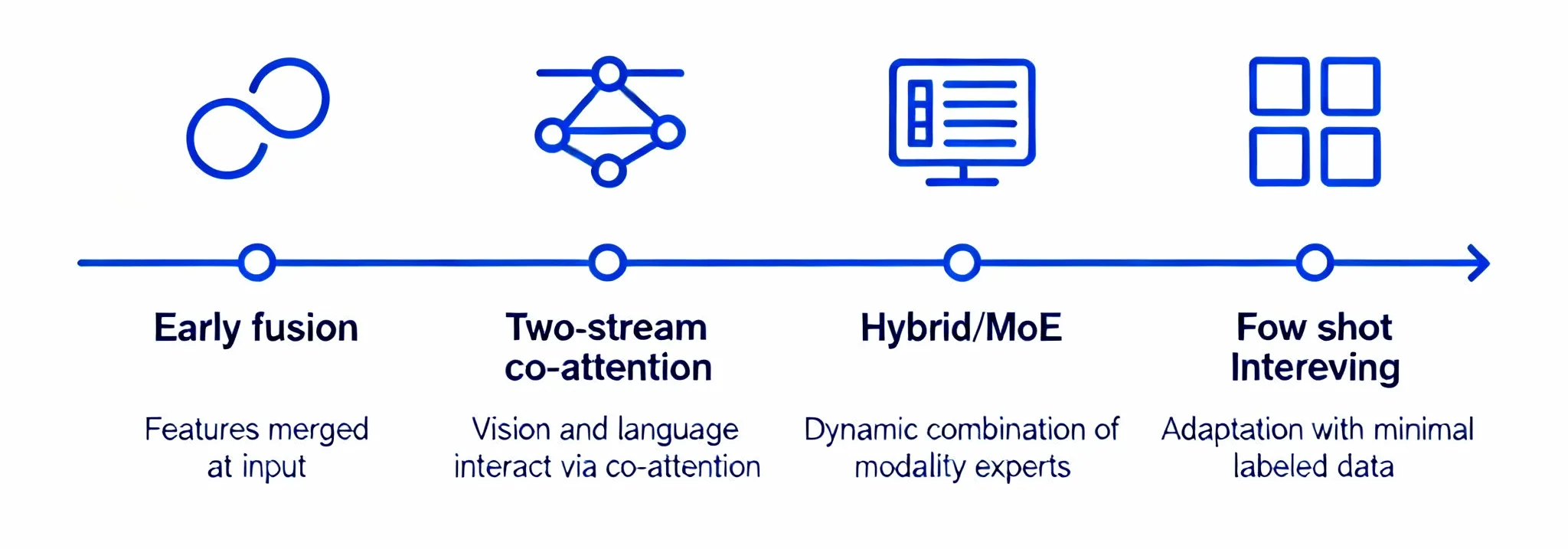
Early and Influential Architectures
Several early VLMs crystallized now-canonical ideas:
- -VisualBERT integrates visual region features with textual tokens to support tasks such as VQA and image–text matching.
- -ViLBERT adopts a two-stream design, processing vision and language separately and coupling them through co-attention layers.
- -VLMo proposes a mixture of modality experts transformer that can operate as a dual encoder or as a fusion encoder, enabling efficiency for retrieval and expressivity for generation.
- -Flamingo demonstrates few-shot interleaved vision–text processing, excelling where task-specific data is scarce and flexible conditioning is needed.
These systems highlight two broad families: dual encoders (efficient retrieval via contrastive alignment) and fusion models (token-level grounding via cross-attention), with hybrids that share or switch modes depending on the downstream task.

Architectures
1. Vision Encoders
Historically, CNNs provided the backbone for extracting regional features such as objects and attributes. Modern VLMs increasingly favor Vision Transformers (ViTs), which partition images into fixed-size patches, treat each as a token, and apply self-attention to capture long-range dependencies. ViTs produce dense visual embeddings suitable for alignment into a joint space or cross-attention fusion with text capabilities that are especially valuable in AI defect detection systems where precise visual feature extraction is critical.
Design considerations
-Resolution vs. cost:
More, smaller patches improve granularity but increase compute.
-Token dropping/pooling:
For efficiency, many systems pool spatial tokens or learn to select informative tokens adaptively.
-Intermediate visual supervision:
Weak auxiliary losses (e.g., masked patch prediction) can stabilize training.
2. Language Encoders and Decoders
Text modules may be encoders (producing contextual token representations) or decoders (generating output text with auto-regressive attention). Some VLMs separate these roles for control and efficiency; others use a unified transformer in encoder–decoder or decoder-only modes, depending on the task and data regime.
Interfaces with vision: The language side can (i) project into a joint embedding space for contrastive objectives; (ii) attend over visual tokens in fusion models; or (iii) perform both, enabling retrieval and generation in one system.
3. Fusion and Alignment Mechanisms
Three mechanisms dominate:
Contrastive Alignment (Dual Encoders):
A vision tower maps Ito vwhile a text tower maps Tto t. Training maximizes similarity for matched pairs and separates mismatched pairs in a shared embedding space. This yields fast nearest-neighbor retrieval and scalable indexing.
Cross-Attention Fusion (Single or Two-Stream Fusion):
Visual tokens and textual tokens exchange information through attention blocks, enabling fine-grained grounding and text generation conditioned on visual context. Fusion excels at VQA and descriptive generation but is heavier at inference.
Masked/Generative Objectives:
Models predict masked tokens (vision or language) or generate outputs (captions, rationales) conditioned on images and text, improving robustness and compositional understanding.
4. Hybrid and Switchable Designs

Training Paradigms
Pretraining on Image–Text Pairs
Most VLMs begin with large-scale pretraining on weakly aligned image–text pairs (alt-text, captions) using contrastive, generative, masked, or combined objectives. Pretraining induces a shared grounding between visual concepts and linguistic tokens that generalizes across tasks.
Fine-Tuning and Task Adaptation
For specific tasks-captioning, VQA, retrieval-models are fine-tuned with task-appropriate heads, prompts, or instruction formats. Semi-/self-supervised strategies further leverage unlabelled data to stabilize learning and improve out-of-distribution (OOD) robustness.
Few-/Zero-Shot and In-Context Learning
Architectures like Flamingo emphasize few-shot capabilities via interleaved vision–text conditioning, showing strong performance when only a handful of exemplars are available. This property is invaluable when labeled data is limited or rapid adaptation is crucial.
Practical Considerations
- -Curriculum & data mixtures: Combining contrastive and generative phases can yield complementary strengths (retrieval vs. grounded generation).
- -Augmentations: Vision-side cropping and color jitter, and text-side paraphrasing or masking, can improve invariances.
- -Instruction-tuning: Formatting prompts as instructions and providing high-quality demonstrations improves alignment for interactive applications.

Evaluation: Tasks, Datasets, and Metrics
Rigorous evaluation requires multiple lenses: generation quality, accuracy on discrete tasks, retrieval effectiveness, and generalization under few-shot or OOD conditions.
Core Tasks
-Image Captioning:
Generate a descriptive sentence or paragraph for an image.
-Visual Question Answering (VQA):
Produce a short answer to a natural-language question about the image.
-Cross-Modal Retrieval:
Rank images given text (or text given images).
-Natural Language Visual Reasoning (e.g., NLVR2):
Assess grounded logical reasoning over images and captions.
Benchmarks and Metrics
Common datasets include Conceptual Captions, Flickr30k, VQA datasets, and NLVR2. Captioning is typically scored using BLEU, CIDEr, and SPICE; VQA and NLVR2 with accuracy; retrieval with Recall@K or mean Average Precision (mAP). Zero-/few-shot performance is reported to measure generalization without extensive fine-tuning.
Evaluation Protocols
Key protocol choices include: (i) whether to freeze the backbone or fine-tune end-to-end, (ii) prompt formats and instruction templates, (iii) the mixture of datasets used for evaluation to avoid overfitting to a single benchmark, and (iv) OOD tests that perturb style, context, or composition.
Toward Robustness
Generalization beyond the ‘dataset milieu’ remains a central challenge; strong benchmark scores can mask brittleness under unusual compositions, long-tail attributes, or domain shift. Evaluations should incorporate OOD splits, compositional probes, and qualitative failure analysis.
Applications and Deployment Patterns
VLMs are already embedded-experimentally or at scale-in multiple application domains:
-Accessibility & Captioning:
Automatically describing images supports users with visual impairments and improves content discoverability.
-Interactive Assistants:
Users can ask questions about photos (e.g., “How many people are wearing helmets?”) or request actions grounded in images.
-Multimodal Search & Retrieval:
Text→image and image→text retrieval improves discovery in media libraries, e-commerce, and knowledge bases.
-Content Moderation & Safety:
Cross-checking imagery with captions or context helps detect inappropriate or misleading content.
-Creative & Generative Workflows:
From story generation grounded in images to tools that transform or compose visual content, including real-world AI visual inspection use cases.
Deployment considerations.
-Latency and throughput:
Cross-attention fusion can be computationally heavier than dual encoders at inference-relevant for real-time assistants.
-Indexing and retrieval:
Dual encoders support large-scale vector search with approximate nearest neighbor (ANN) indexing.
-Privacy and compliance:
Applications that process user images must handle sensitive data appropriately.
Risks, Limitations, and Ethics
Despite their promise, VLMs face substantive risks and open problems:
Bias and Representation.
Datasets are often skewed across cultures, genders, and geographies; models trained on such data can reflect or amplify those biases. This manifests in stereotyped captions or uneven error rates across demographics. Mitigations include balanced data curation, bias-aware training objectives, and post-hoc audits.
Generalization vs. Overfitting.
High performance on curated benchmarks can hide brittle behaviors when exposed to out-of-distribution content or unusual compositions. Techniques such as stronger data diversity, compositional training targets, and adversarial or counterfactual probes help reveal and address gaps.
Interpretability and Explainability
While attention visualizations offer some insight, they do not constitute faithful explanations of the underlying reasoning. Achieving more transparent behavior requires causal analyses, counterfactual testing, and potentially auxiliary objectives that promote disentangled, human-meaningful factors.
Hallucination and Reliability
Predictive analytics for enterprise intelligence can help identify when VLMs output plausible but incorrect statements-e.g., describing objects not present or miscounting entities-posing risks in safety-critical settings (medical, industrial, legal). Guardrails include calibrated confidence measures, detection of ungrounded claims, and human-in-the-loop review for high-stakes use.
Privacy and Consent
Images often contain personal, sensitive, or proprietary information. Training and deployment must consider consent, storage policies, and mechanisms for data deletion and minimization. Privacy-preserving learning and on-device inference can reduce exposure.
Compute, Cost, and Environment
Training and serving large VLMs demands significant compute and memory, raising environmental and economic concerns. Efficient architectures, distillation, quantization, and sparsity can reduce resource usage.

Design and Engineering Patterns
Choosing an Architecture.
- -Prefer dual encoders when retrieval scale and latency are paramount; you need to embed millions of items and search quickly.
- -Prefer fusion models when fine-grained grounding and generative outputs are central (e.g., VQA with step-by-step rationales).
- -Consider hybrid patterns (or MoE routing) to combine retrieval efficiency with grounded generation.
Data Strategy
- -Combine web-scale noisy pairs with curated high-quality datasets.
- -Apply data filtering (e.g., image–text alignment thresholds) to improve signal-to-noise.
- -Incorporate counterfactuals and synthetic augmentations to stress compositionality.
Inference and Serving
- -Cache and reuse image embeddings for retrieval; separate online (query) vs. offline (gallery) computation.
- -Use adaptive token selection (e.g., keyframe sampling for video, patch pooling) to cut latency.
- -Monitor calibration; expose uncertainty to downstream systems where feasible.

Case Study Style Summaries of Representative Models
While a full historical survey is beyond scope, brief synopses clarify the landscape:
-VisualBERT:
Unified transformer integrates region features and text tokens for VQA and image–text tasks; emphasizes early fusion of modalities.
-ViLBERT:
Two-stream transformer with co-attention, enabling separate modality specialization with points of interaction; strong for tasks needing token-level grounding.
-VLMo:
Mixture-of-experts approach capable of dual or fusion operation, supporting both retrieval efficiency and generative depth within one framework.
-Flamingo:
Few-shot interleaved vision–text design; excels in scenarios where the model must condition flexibly on small numbers of examples and mixed modalities.
Toward Interactive and Agentic VLMs
Autonomous AI agents for enterprise workflows represent a growing frontier beyond static captioning or QA, involving interactive assistants and agents that follow instructions referencing visual scenes, maintain context across turns, and take actions (e.g., in a GUI or robotics environment). Achieving reliable agentic behavior requires stronger temporal grounding, action-conditional reasoning, and external tool use, while integrating safety checks for visual hallucinations and affordance errors.
Governance, Safety, and Responsible Deployment
Policy and governance must keep pace with capability. Practical measures include:
-Data governance:
Document data sources, consent mechanisms, and known gaps; support data redaction and deletion.
-Bias audits and red-teaming:
Evaluate error disparities and prompt-based failure modes across demographics; maintain audit trails.
-Usage controls:
Enforce content policies, logging, and rate limits; add human review for high-risk domains.
-Transparency artifacts:
Provide model cards detailing intended use, limitations, and safety mitigations.
-Sustainability targets:
Track compute efficiency and environmental impact; prefer efficient training and serving strategies.
Trends and Future Directions
The next wave of VLM research and practice appears to concentrate on the following thrusts:
1. Efficiency and Lightweight Models:
Following an AI transformation roadmap for enterprise organisations, distillation, quantization, token pruning, and architectural simplifications aim to make VLMs edge-ready for mobile and embedded use.
2. Better Multimodal Alignment and Reasoning:
Moving beyond co-occurrence to causal and temporal understanding; enabling compositional generalization and commonsense reasoning about scenes.
3. Improved Few-/Zero-Shot Learning:
Reducing reliance on labeled data and accelerating adaptation with minimal supervision.
4. Safety, Fairness, and Governance:
Building in safeguards, auditability, and continuous monitoring as VLMs proliferate.
5. Beyond Image + Text:
Integrating video and audio, possibly other sensors, to capture richer context; aligning perception with action in robotics.
6. Interactivity and Embodied Agents:
Dialog-capable models that reference images, follow instructions, and guide or control devices.

Open Research Questions
-Grounded Consistency:
How can we ensure generated text remains faithful to the visual evidence across long contexts?
-Counterfactual Reasoning:
Can models reliably reason about what would change in the scene under hypothetical interventions?
-Temporal Reasoning:
What are principled architectures for reasoning over sequences of frames and aligning them with narrative text?
-Learning from Sparse Feedback:
How can reinforcement learning or preference optimization be used without inducing new biases?
-Evaluation Beyond Benchmarks:
What new tests can meaningfully probe compositionality, causality, and safety?

Conclusion
Vision–Language Models connect visual perception with linguistic understanding. Ready to explore how VLMs can transform your enterprise? Speak with Ombrulla AI specialists to discuss your multimodal AI strategy., unlocking a spectrum of tasks from captioning and VQA to retrieval and interactive assistance. Architecturally, they range from dual encoders optimized for scalable retrieval to fusion models offering fine-grained grounding and generation; hybrids promise the best of both. Training combines contrastive alignment, cross-attention fusion, and masked/generative objectives, typically in large-scale pretraining followed by task-specific fine-tuning or instruction-tuning. Evaluations span captioning, VQA, retrieval, and reasoning, with increasing emphasis on OOD robustness and few-/zero-shot generalization. Applications are expanding rapidly-accompanied by legitimate concerns over bias, privacy, hallucination, interpretability, and compute cost. Addressing these responsibly requires governance, safety-by-design, and transparency.The near future will feature more efficient, better-aligned, and more interactive VLMs, expanding into video, audio, and agentic behaviors. As researchers and engineers continue refining architectures, training regimes, and evaluations, the field moves toward trustworthy systems that can see and speak with reliability and care.
The near future will feature more efficient, better-aligned, and more interactive VLMs, expanding into video, audio, and agentic behaviors. As researchers and engineers continue refining architectures, training regimes, and evaluations, the field moves toward trustworthy systems that can see and speak with reliability and care.
Acknowledgments
This paper synthesizes and deepens the content of an internal primer on VLMs, expanding it into a research-paper format with additional analysis and structure.
References
- Li, L. H., Yatskar, M., Yin, D., Hsieh, C. J., & Chang, K. W. (2019). Visualbert: A simple and performant baseline for vision and language. arXiv preprint arXiv:1908.03557.[arxiv]
- Lu, J., Batra, D., Parikh, D., & Lee, S. (2019). Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. Advances in neural information processing systems, 32.[neurips]
- Alayrac, J. B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., ... & Simonyan, K. (2022). Flamingo: a visual language model for few-shot learning. Advances in neural information processing systems, 35, 23716-23736.[neurips]
- Bao, H., Wang, W., Dong, L., Liu, Q., Mohammed, O. K., Aggarwal, K., ... & Wei, F. (2022). Vlmo: Unified vision-language pre-training with mixture-of-modality-experts. Advances in neural information processing systems, 35, 32897-32912.[neurips]
- Raghu, M., Unterthiner, T., Kornblith, S., Zhang, C., & Dosovitskiy, A. (2021). Do vision transformers see like convolutional neural networks?. Advances in neural information processing systems, 34, 12116-12128.[neurips]