Edge AI on Mobile Devices for Real-Time Asset Assessment
Abstract
As organizations deploy mobile artificial-intelligence (AI) inspection tools at scale, dependence on cloud-based inference is increasingly constrained by bandwidth, latency, and data-residency requirements. Edge AI, defined here as model inference executed directly on smartphones and tablets, allows a mobile inspection application to perform asset assessment in real time, including in low-connectivity and hazardous environments. Recent progress in lightweight architectures such as MobileNet, EfficientNet-Lite, and the YOLOv5n/YOLOv8n nano detector family, combined with mature on-device runtimes including TensorFlow Lite, ONNX Runtime Mobile, and Core ML, has made practical on-device inspection deployments feasible on commodity mobile hardware.
This paper investigates on-device inference for real-time asset assessment. We characterize model families suited to mobile deployment, including MobileNet variants, YOLOv5n, and related nano detectors; discuss optimization techniques including quantization, pruning, and knowledge distillation; and present an evaluation framework spanning latency, accuracy, and battery consumption under field-representative conditions. We situate these techniques within a mobile inspection workflow in which a field application captures images or video of physical assets such as valves, gauges, panels, and structural elements, and uses an on-device model to detect defects, read instruments, and annotate findings. We synthesize results from recent benchmarks on edge-device inference, mobile object detection, and energy profiling, finding that quantized YOLOv5n and MobileNet variants can frequently achieve sub-100-millisecond per-frame latency on contemporary smartphones, with acceptable accuracy trade-offs and modest battery impact when inference is properly batched and throttled. We conclude with design patterns for integrating on-device models into mobile inspection workflows, balancing real-time feedback, power management, and user experience, and outline open research questions in adaptive model selection, dynamic quality-of-service control, and standardized energy benchmarking for mobile edge AI.
Introduction
Enterprise asset inspection, covering infrastructure, manufacturing lines, utilities, and buildings, is transitioning from paper checklists to mobile, AI-assisted workflows. Field technicians increasingly use a mobile inspection application on a smartphone or tablet to capture photographs, video, and notes, while an embedded model highlights defects, misconfigurations, or non-compliance in near real time.
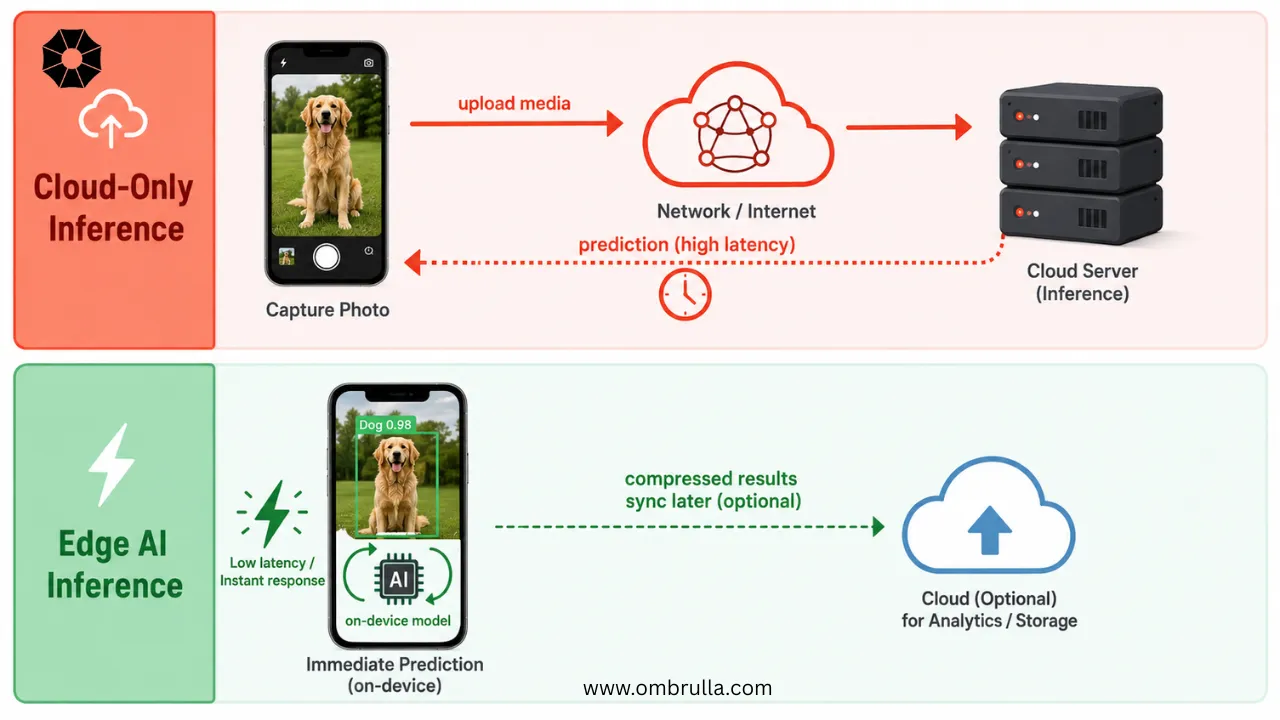
A common first implementation of this pattern runs the model exclusively in the cloud: the mobile application uploads captured media, awaits a server-side prediction, and displays the result once it returns. In practice, this architecture quickly encounters four recurring limitations.
- -Latency: round-trip delays, particularly over cellular or satellite links, disrupt inspection flow and discourage adoption by field personnel.
- -Connectivity: mines, offshore platforms, and remote substations often have intermittent or no network connectivity during an inspection.
- -Data sensitivity: images and video of critical infrastructure may be sensitive, and transmitting all raw media to the cloud can violate internal policy or regulatory requirements.
- -Cost: high volumes of uploaded media drive recurring bandwidth and cloud-compute expenditure.
Edge AI, in which inference is executed directly on the device, addresses each of these constraints by embedding a lightweight model inside the mobile application itself. Improvements in model architecture, mobile system-on-chip (SoC) design (particularly dedicated neural processing units and neural engines), and inference runtimes have collectively enabled YOLO- and MobileNet-family models to run interactively on mid-range smartphones. Recent comparative studies of MobileNet, EfficientDet, YOLOv5, YOLOv8, and related backbones on mobile and embedded platforms consistently highlight a three-way trade-off between accuracy, model size, and latency that practitioners must navigate for a given deployment.
Within a mobile-first inspection workflow, on-device inference allows the application to draw bounding boxes around candidate defects as the inspector frames a shot, provide instant capture-quality feedback such as prompting the user to move closer or improve lighting, and cache only compressed embeddings or summary results locally, thereby reducing the volume of sensitive data that must leave the device. This paper focuses on three related contributions: a characterization of model and runtime choices for on-device asset assessment, including MobileNet, YOLOv5n, and related nano-scale models; an evaluation framework spanning latency, accuracy, and battery impact under field-representative conditions; and a set of architectural patterns for integrating edge AI into mobile inspection applications.
Related Work
Research relevant to this paper spans three areas: efficient neural network architectures for resource-constrained devices, on-device inference runtimes and hardware acceleration, and applied computer vision for industrial and infrastructure inspection.
Efficient architecture design has been driven primarily by depthwise separable convolutions, as introduced in the MobileNet family, and by compound scaling approaches such as EfficientNet, both of which substantially reduce parameter count and floating-point operations relative to standard convolutional backbones while retaining competitive accuracy. In object detection, the YOLO family has progressively introduced nano-scale variants, including YOLOv5n and YOLOv8n, that reduce channel width and network depth specifically to support real-time inference on mobile and embedded hardware. These architectural advances are typically combined with post-training quantization, quantization-aware training, structured or unstructured pruning, and knowledge distillation to further reduce model size and inference cost with minimal accuracy degradation.
A parallel body of work addresses the runtime and systems layer: TensorFlow Lite, ONNX Runtime Mobile, and Apple's Core ML each provide hardware-accelerated execution paths that exploit neural processing units, GPUs, or dedicated neural engines available on modern mobile SoCs. Energy-focused studies of mobile deep learning inference report that model size, precision, and hardware delegate choice substantially affect energy consumption per inference, motivating careful co-design of model and deployment configuration rather than treating model accuracy as the sole optimization target.
Within the inspection domain specifically, prior work on computer-vision-based industrial inspection frameworks has generally emphasized cloud or on-premises server deployment, with edge deployment treated as a secondary or future consideration. This paper differs by treating on-device inference as the primary design point, and by proposing an evaluation framework that jointly considers latency, accuracy, and battery consumption, three dimensions that are rarely benchmarked together in the existing literature despite their joint influence on field usability.
Background: Edge AI Models and Mobile Runtimes
Lightweight Model Families
Several model families are designed explicitly for mobile and embedded deployment, and form the architectural foundation for the remainder of this paper.
- -MobileNet V1 to V3: use depthwise separable convolutions to reduce floating-point operations and parameter count, and are widely used as backbone networks for both classification and detection tasks.
- -EfficientNet-Lite and EfficientNetV2-Small: apply compound scaling and neural architecture search to improve the accuracy-efficiency trade-off relative to manually designed backbones.
- -YOLO nano variants (YOLOv5n, YOLOv8n): are compact object detectors optimized for edge devices through reduced channel width and network depth. Public benchmarks report that YOLOv5n achieves real-time inference on mobile SoCs and embedded platforms such as the Raspberry Pi and NVIDIA Jetson families.
These architectures are typically combined with two classes of compression technique: quantization, in which model weights and activations are represented at 8-bit or mixed precision rather than 32-bit floating point, reducing both model size and inference latency; and structured or unstructured pruning together with knowledge distillation, which further reduce model complexity by removing redundant parameters or transferring knowledge from a larger teacher model to a smaller student model.
Mobile AI Runtimes
On-device inference is delivered through one of several mature runtimes. TensorFlow Lite supports quantization-aware training, hardware acceleration through the Android Neural Networks API (NNAPI) and GPU delegates, and a dedicated model-optimization toolkit. ONNX Runtime Mobile deploys models in the ONNX interchange format with mobile- and embedded-specific optimizations, and is commonly used alongside YOLO and other detection architectures. Core ML, available on iOS, integrates directly with Apple's Neural Engine and is widely used for on-device vision tasks on iPhone and iPad hardware. Collectively, these runtimes allow a mobile application to package one or more models and execute them locally with minimal application-level code, which aligns well with the latency and privacy requirements of field inspection use cases.
Lightweight model families are designed explicitly for mobile and embedded deployment. MobileNet (V1-V3) uses depthwise separable convolutions to reduce operations and parameters. EfficientNet-Lite and EfficientNetV2-Small apply compound scaling and neural architecture search. YOLO nano variants (YOLOv5n, YOLOv8n) are compact object detectors optimized through reduced channel width and depth.
These architectures are combined with two compression classes: quantization (8-bit or mixed precision, reducing size and latency) and pruning with knowledge distillation (removing redundant parameters). On-device inference is delivered through mature runtimes: TensorFlow Lite (Android/iOS), ONNX Runtime Mobile (cross-platform), and Core ML (iOS). These runtimes support quantization-aware training and hardware acceleration through NNAPI and GPU delegates.
| Component Type | Primary Use Case | Platform / Runtime Support |
|---|---|---|
| MobileNetV1-V3 | CNN backbone (classification/detection); component classification, lightweight feature extraction | TensorFlow Lite, Core ML, ONNX Runtime Mobile |
| EfficientNet-Lite / EfficientNetV2-S | CNN backbone; higher-accuracy classification under tight compute budgets | TensorFlow Lite, ONNX Runtime Mobile |
| YOLOv5n / YOLOv8n | Nano object detector; real-time component and defect detection | TensorFlow Lite, ONNX Runtime Mobile, Core ML (via conversion) |
| TensorFlow Lite | Inference runtime; Android/iOS/embedded on-device execution | NNAPI, GPU delegate, Hexagon DSP |
| ONNX Runtime Mobile | Inference runtime; cross-platform on-device execution | Android, iOS, embedded Linux |
| Core ML | Inference runtime; iOS/iPadOS on-device execution | Apple Neural Engine, GPU, CPU |
System Architecture for Mobile-Based Asset Assessment
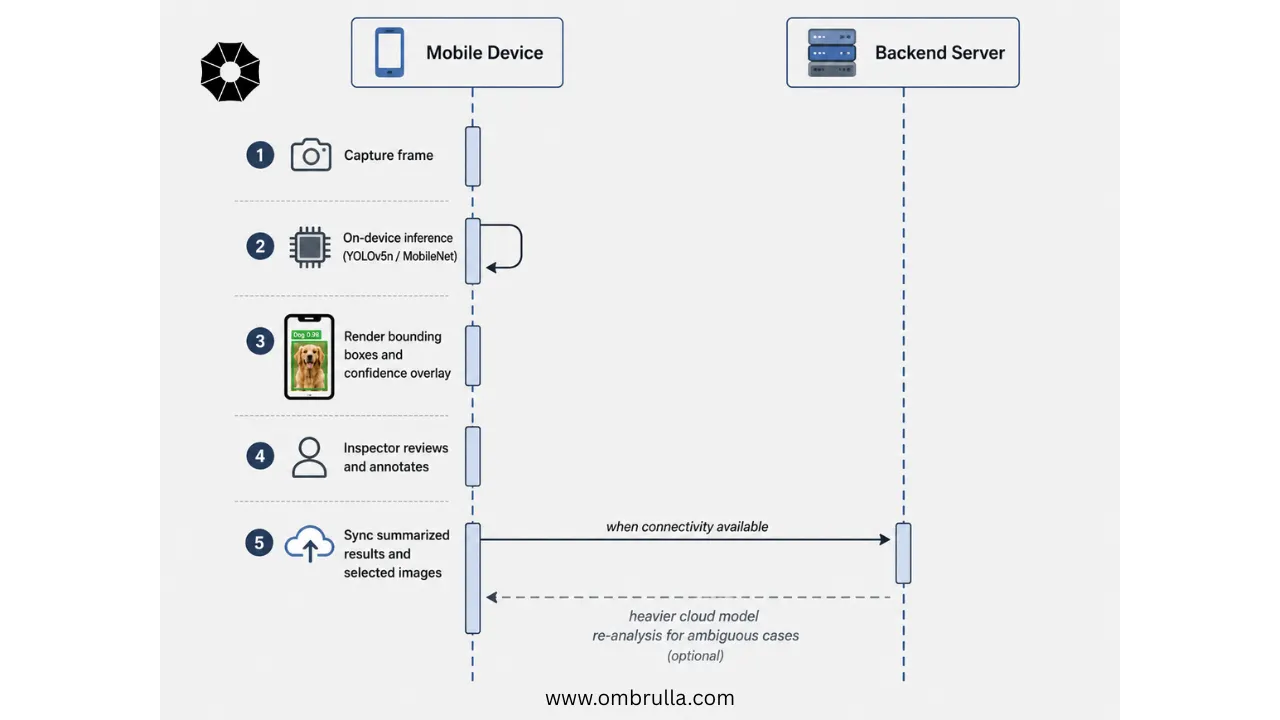
Within a mobile inspection workflow, on-device inference sits inside a broader, five-stage process. In the capture stage, the mobile application uses the device camera to capture frames of an asset, such as a pump, valve, or electrical panel. In the on-device inference stage, a lightweight model, for example YOLOv5n or a MobileNet-based detector, runs in real time to detect defects, components, or gauges within the captured frame. In the feedback stage, the application overlays bounding boxes and labels, indicates model confidence, and may prompt the inspector for an additional image if capture quality is poor, for example due to blur or occlusion. In the annotation and decision stage, the inspector reviews the AI-generated suggestions, confirms or corrects them, and adds notes or voice memos as needed. Finally, in the synchronization stage, the application stores results locally and synchronizes them to a backend system once connectivity becomes available, optionally triggering a heavier cloud-based model for ambiguous or high-risk cases.
Edge AI therefore functions as a front-end accelerator for asset assessment, while heavier back-end models and analytics continue to run in the cloud or on-premises servers for cases that warrant deeper analysis.
Model Optimization for On-Device Inference
Tailoring MobileNet and YOLOv5n for Asset Assessment
Deploying MobileNet or YOLOv5n in a mobile inspection context typically involves a four-step adaptation process. The practitioner first selects an architecture variant with reduced width and depth, such as MobileNetV3-small or YOLOv5n itself, then trains or fine-tunes the selected model on a domain-specific dataset of asset images covering pumps, valves, panels, cracks, and corrosion. Post-training quantization, commonly to 8-bit integer precision, is then applied to reduce model size and improve inference speed; where accuracy loss from post-training quantization is unacceptable, quantization-aware training can be used instead to better preserve accuracy. Finally, light structured pruning may be applied to remove redundant channels without materially affecting detection quality.
Reports and open-source experiments indicate that quantized YOLOv5n models can shrink from tens of megabytes to a few megabytes in size while delivering faster inference, with only minor mean average precision (mAP) degradation on typical detection tasks. This combination of size reduction and speed improvement is what makes real-time, on-device inference practical on commodity mobile hardware.Task Types for Mobile Asset Assessment
Edge AI models deployed within mobile inspection applications typically support three task categories. Component detection involves locating valves, gauges, flanges, bolts, and cables within a frame. Defect detection involves identifying cracks, corrosion, leaks, or missing labels. Gauge reading and optical character recognition (OCR) involve reading analog meter needles or digital displays using lightweight OCR models. Different tasks frequently use different backbones in combination; for example, a deployment may use YOLOv5n for object and defect detection alongside a MobileNet-based classification head for overall condition grading.
| Technique | Mechanism | Typical Size/Latency Impact | Typical Accuracy Impact |
|---|---|---|---|
| Post-training quantization (INT8) | Converts weights/activations from FP32 to INT8 after training | 2-4x size reduction, 1.5-3x latency improvement | Small (0-2 mAP points) on well-behaved models |
| Quantization-aware training | Simulates quantization noise during training | Similar to post-training quantization | Minimal; recovers most accuracy lost to PTQ |
| Structured pruning | Removes redundant channels/filters | 10-50% additional size/latency reduction | Small to moderate depending on ratio |
| Knowledge distillation | Trains small student model to mimic larger teacher | No direct size change; enables smaller architectures | Can improve accuracy relative to training from scratch |
Evaluation Framework: Latency, Accuracy, and Battery Consumption
Because field usability depends jointly on responsiveness, predictive maintenance, and device endurance, this paper proposes an evaluation framework spanning three dimensions: latency and throughput, accuracy and robustness, and battery consumption. Each dimension is discussed in turn, followed by a consolidated metrics summary.
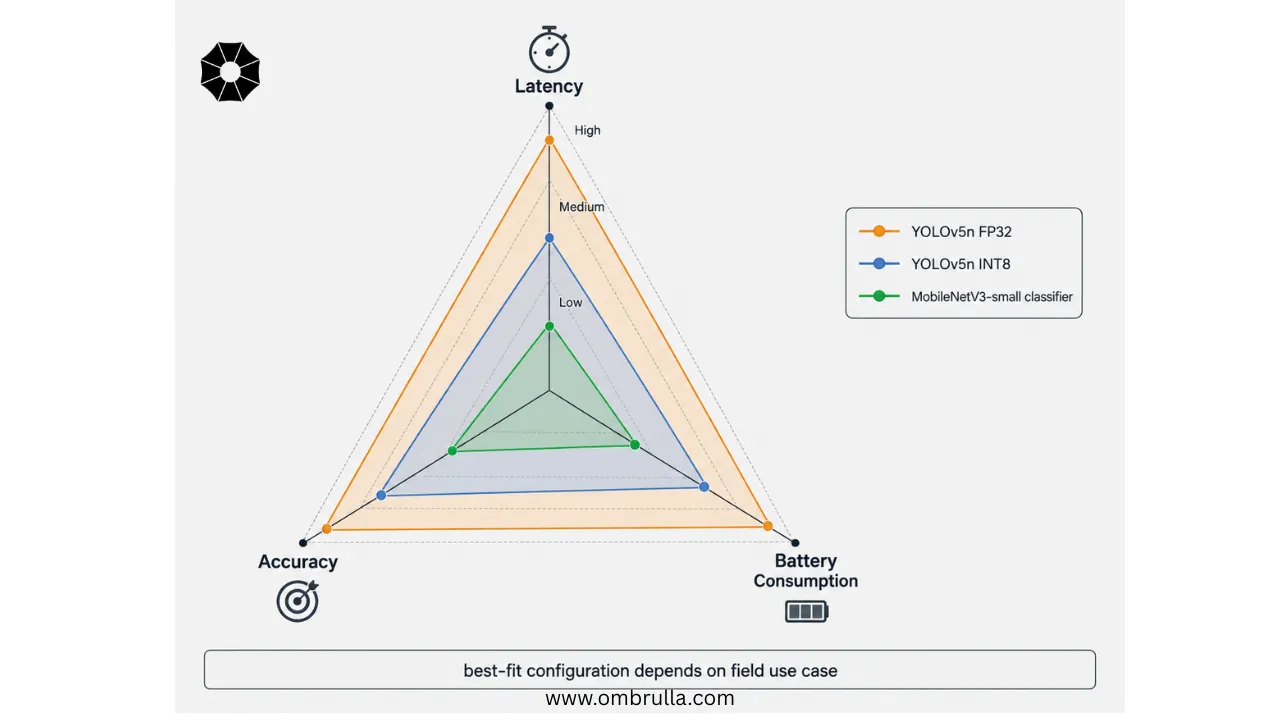
| Model Configuration | Typical Per-Frame Latency | Typical Accuracy Profile | Relative Battery Impact |
|---|---|---|---|
| YOLOv5n, FP32 | 40-70 ms (mobile GPU/CPU) | Highest among nano detectors | High |
| YOLOv5n, INT8 quantized | 10-30 ms (GPU/NNAPI) | Slightly reduced vs. FP32, within 1-3 mAP | Moderate |
| MobileNetV3-small | < 10 ms | Task-dependent; strong for single-label grading | Low |
| Hybrid edge-filter + cloud | Edge: < 30 ms; cloud: network-dependent | Approaches cloud-model accuracy for flagged cases | Low to moderate |
Latency and Throughput
For a mobile application used in the field, latency directly affects user experience. Vendor and independent benchmarks on edge devices report that YOLOv5n running on a mid-range Android device with GPU or NNAPI acceleration can achieve approximately 10 to 30 milliseconds per 640-by-640-pixel frame, depending on hardware and the chosen hardware delegate, while MobileNetV3-small classification on comparable devices can run in well under 10 milliseconds per image.
An evaluation plan for mobile asset assessment should measure three latency components: cold-start latency, the time from launching the application to the first completed inference, which matters when inspectors open the application sporadically rather than continuously; per-frame inference latency, measured separately for single-shot captures and for short video bursts; and end-to-end interaction latency, the time from pressing the capture control to the AI overlay appearing on screen. Profiling tools such as Android Systrace and Perfetto, together with the built-in profilers provided by TensorFlow Lite and ONNX Runtime, support measurement of these metrics under realistic conditions.Accuracy and Robustness
On-device models are typically smaller, and therefore potentially less accurate, than their cloud-scale counterparts. Evaluation should accordingly include standard detection metrics, namely mAP, precision, and recall, computed on a held-out, domain-specific test set, alongside robustness testing under varying lighting conditions (including dark and backlit scenes), motion blur and varying camera distance, and device-specific variation across different phone models, lenses, and sensors. In some deployments, a hybrid strategy is used in which the edge model performs an initial filter and pre-classification, while a more accurate cloud model asynchronously re-evaluates high-risk or low-confidence samples.
Battery Consumption
Battery life is a key constraint for mobile inspection, particularly during long shifts or in remote environments without convenient charging access. Energy studies of mobile inference report that continuous deep-model inference can substantially increase power draw, particularly when relying on GPU execution or sustained high CPU clock frequency, and that quantized, smaller models significantly reduce energy consumption per inference relative to full-precision, larger counterparts.
Integration Patterns: On-Device, Hybrid, and Cloud-Assisted Deployment
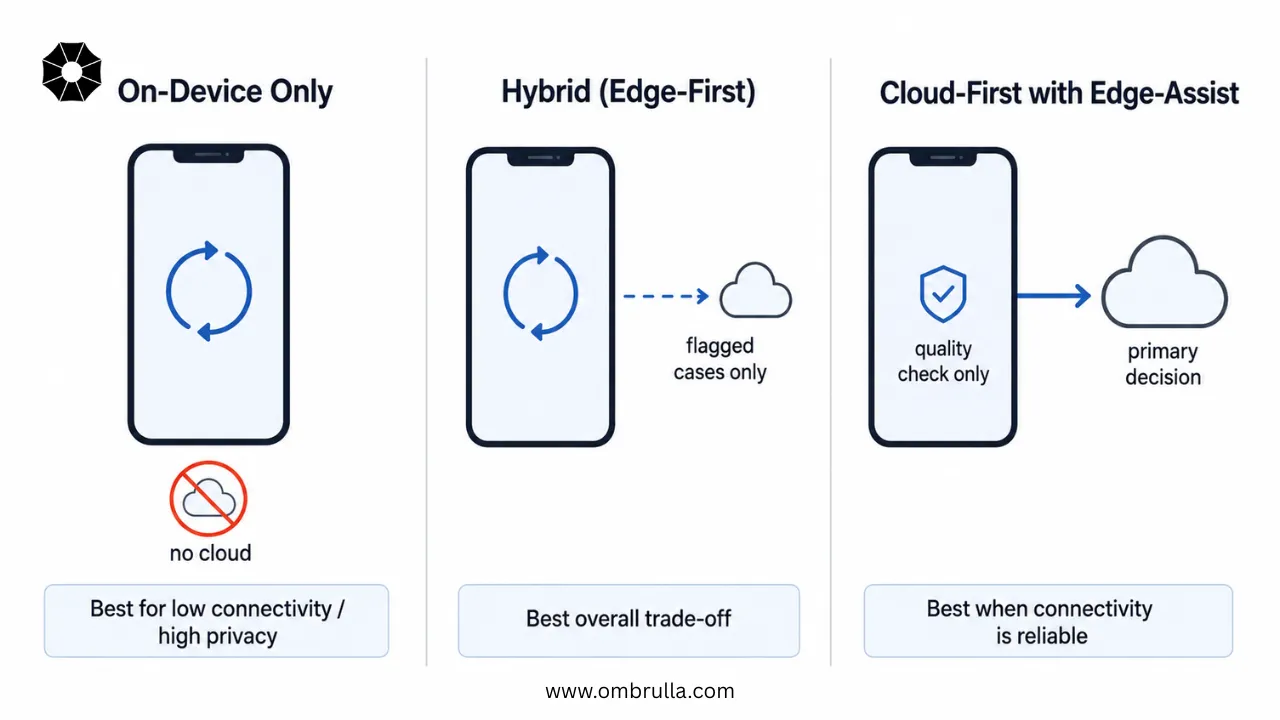
On-Device-Only versus Hybrid Architectures
Three deployment patterns recur across AI mobile inspection implementations. In the on-device-only pattern, all inference runs locally on the device, with the server limited to storing results and media; this pattern is best suited to low-connectivity, high-privacy environments where cloud round-trips are undesirable or infeasible. In the hybrid, edge-first pattern, the application runs a lightweight model on-device for immediate feedback, while high-risk or low-confidence cases are flagged for asynchronous cloud re-analysis using a heavier model once connectivity becomes available; this pattern suits environments with intermittent connectivity. In the cloud-first-with-edge-assist pattern, edge models provide only preliminary guidance, such as framing or capture-quality checks, while the primary detection or classification decision relies on cloud models once data is uploaded. For most mobile asset assessment use cases, hybrid architectures deliver the best overall trade-off, combining instant on-device feedback with cloud-level accuracy whenever connectivity permits.
Scheduling and Throttling
To avoid draining battery and overloading the device, three scheduling practices are recommended. Inference should run primarily on user-triggered captures rather than continuous streaming, unless a genuinely real-time stream is required by the use case. Dynamic resolution scaling should be used, applying lower resolution for live framing previews and higher resolution only for the final captured frame. Hardware accelerators, including NNAPI and the Apple Neural Engine, should be used when available, with a graceful software fallback when they are not.
Model Updates and Governance
Edge-deployed models require lifecycle management analogous to any other production software artifact. This includes maintaining a versioned model registry in the backend system, delivering signed model artifacts over secure channels to prevent tampering, and using staged rollouts to a subset of devices with performance monitoring before broader deployment. Such governance is critical both for maintaining inspection quality and for reconciling differences between model versions when analyzing historical inspection data collected under earlier model generations.
Case Studies
This section presents two illustrative case-study templates that demonstrate how the architectural and evaluation principles described in Sections 4 through 7 apply to specific inspection scenarios. These templates are intended as design references rather than reports of completed field trials.
Case Study A: Pump and Valve Inspection with YOLOv5n
The goal of this case study is real-time detection of valves, gauges, and leaks for a process plant. The edge model is YOLOv5n, quantized to int8 precision and executed through TensorFlow Lite or ONNX Runtime Mobile. In the corresponding workflow, the inspector points the mobile application at a pump skid; the application draws bounding boxes on detected valves, gauges, and suspected leaks; and the inspector taps on individual boxes to confirm or correct the AI-generated annotations, after which results are stored locally. Representative evaluation targets for this scenario are per-frame inference latency below 60 milliseconds on mid-range Android devices, battery drain below 10 percent over a standard two-hour inspection route, and detection accuracy reported as mAP against a manually labeled ground-truth set.
Case Study B: Electrical Panel Assessment with MobileNet and a Lightweight Detection Head
The goal of this case study is to detect missing covers, open doors, and panel labels, and to classify panel type. The edge model is a MobileNetV3-small feature extractor paired with a custom detection head. In the corresponding workflow, the inspector uses the mobile application to capture front-view images of the panel; the on-device model immediately flags uncovered live parts and missing labels, and the AI overlay indicates the associated risk level. Evaluation for this scenario should compare inspection time and error rate against a manual-only baseline, and should measure energy consumption and application responsiveness across multiple device classes.
| Case Study | Edge Model | Workflow Summary | Evaluation Targets |
|---|---|---|---|
| Pump and Valve Inspection | YOLOv5n, INT8 quantized (TFLite/ONNX Runtime Mobile) | Point-and-detect valves, gauges, leaks; tap to confirm/correct; local storage | < 60 ms/frame; < 10% battery drain over 2-hour route; mAP vs. ground truth |
| Electrical Panel Assessment | MobileNetV3-small + custom detection head | Capture front-view image; flag uncovered live parts/missing labels with risk overlay | Inspection time and error rate vs. manual baseline; energy use and responsiveness across devices |
Pump and Valve Inspection: Goal is real-time detection of valves, gauges, and leaks for a process plant. Edge model is YOLOv5n quantized to int8 and executed through TensorFlow Lite. Inspector points application at pump skid; bounding boxes appear on detected components and suspected leaks. Inspector taps boxes to confirm or correct annotations; results stored locally. Targets: <60ms/frame latency, <10% battery drain over 2-hour route, detection accuracy vs. manually labeled ground truth.
Electrical Panel Assessment: Goal is to detect missing covers, open doors, and panel labels, and classify panel type. Edge model is MobileNetV3-small feature extractor paired with custom detection head. Inspector captures front-view images; on-device model immediately flags uncovered live parts and missing labels with risk level overlay. Evaluation compares inspection time and error rate against manual-only baseline, and measures energy consumption and responsiveness across device classes.
Open Research Questions
Several research questions remain open around edge AI on mobile devices for real-time asset assessment.
- -Adaptive model selection: dynamically choosing between multiple candidate models, for example an ultra-fast low-accuracy model versus a slower high-accuracy model, based on battery state, device temperature, or the criticality of the asset under inspection.
- -Co-design of models and user experience: optimizing not only accuracy and latency in isolation, but also how quickly inspectors can interpret AI overlays and act on them in the field.
- -Standardized benchmarks: establishing publicly available datasets and evaluation protocols for mobile edge AI in industrial inspection, including consistent latency and energy metrics across device classes.
- -Privacy-preserving edge learning: exploring federated learning or on-device adaptation so that deployed models can improve using inspection data without transmitting raw images off-device.
Conclusion
On-device inference using lightweight models such as MobileNet and YOLOv5n is a practical and increasingly essential capability for mobile asset inspection. By embedding optimized models directly within a mobile inspection application, organizations can perform asset assessment in real time, including in remote or bandwidth-constrained environments, while reducing latency, protecting sensitive data, and improving inspector experience.
The analysis of architectures, runtimes, and evaluation criteria presented in this paper indicates that quantized, nano-scale detectors and classifiers can achieve sub-100-millisecond latency on modern smartphones while preserving useful accuracy and maintaining acceptable battery usage, particularly when paired with careful scheduling and hybrid cloud-edge strategies.
For organizations considering adoption, a pragmatic path forward involves four steps: identifying high-value inspection tasks suited to real-time edge AI, such as component or defect detection and gauge reading; prototyping mobile deployments using MobileNet- or YOLOv5n-class models with TensorFlow Lite or ONNX Runtime Mobile; measuring latency, accuracy, and battery consumption under realistic field conditions using the framework proposed in Section 6; and iterating on model architecture, quantization strategy, and user-experience design until the resulting inspection workflow is fast, reliable, and trusted by inspectors. Executed well, edge AI on mobile devices transforms the smartphone into a self-contained, intelligent tool for asset assessment, bringing inference capability directly to the point of work and enabling safer, more efficient, and more data-driven inspection practice.
References
- Ultralytics. "YOLOv5 Documentation – Performance Benchmarks and Deployment on Edge Devices." 2024–2025.[ultralytics.com]
- Bochkovskiy, A., Wang, C.-Y., and Liao, H.-Y. M. "YOLOv4: Optimal Speed and Accuracy of Object Detection." arXiv:2004.10934, 2020.[arxiv]
- Howard, A., et al. "MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications." arXiv:1704.04861, 2017.[arxiv]
- Sandler, M., et al. "MobileNetV2: Inverted Residuals and Linear Bottlenecks." Proceedings of CVPR, 2018.[cvpr]
- TensorFlow. "TensorFlow Lite Model Optimization Toolkit: Quantization and Pruning." Developer documentation, 2024.[tensorflow.org]
- Liang, H., et al. "Energy-Efficient Deep Neural Network Inference on Mobile Devices: A Survey." ACM Computing Surveys, 2023.[acm.org]
- Tan, M., and Le, Q. "EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks." Proceedings of ICML, 2019.[icml.cc]
- Apple. "Core ML and Neural Engine: Deploying ML Models on iOS Devices." Developer documentation, 2024.[apple.com]
- Microsoft. "ONNX Runtime Mobile – High-Performance Inference on Mobile and Embedded Devices." Documentation and benchmarks, 2024.[microsoft.com]
- Ombrulla. "Mobile AI Inspection – AI-Powered Mobile Inspection App." Solution pages and technical briefs, 2023–2025.[ombrulla.com]