Edge Cloud Co‑Design for Low‑Latency Custom AI
Abstract
As enterprises move from prototypes to production-grade systems, latency becomes a critical requirement for enterprise-grade custom AI solutions and real-time AI software. When organizations deploy custom AI retrieval-augmented assistants, extraction pipelines, or tool-using agents, they often need sub-200 ms token streaming, <100 ms classification, and 2–4 second end-to-end task completion to deliver smooth interactive and embedded experiences. Traditional single-tier cloud inference frequently fails to meet these demands due to network variability, privacy requirements, and cost constraints, key challenges for teams building custom AI and custom AI development workflows.
This white paper introduces a co-design blueprint for edge–cloud architectures purpose-built for AI solutions and enterprise AI software development. We cover enterprise AI and IoT platform architectures and deployment strategies. We formalize latency budgets and outline optimal partitioning strategies: lightweight pre-processing, retrieval steps, and partial decoding at the edge, combined with heavyweight reasoning and model execution in the cloud. We also cover model compression techniques, hardware-aware placement, and mechanisms to ensure consistency, privacy, and governance across multi-tenant deployments core considerations for scalable AI software.
Finally, we provide practical resources for engineering teams, including pseudo-code templates, SLO definitions, orchestration patterns, and throughput/latency calculators. The paper also includes image and diagram prompts for system architecture, dashboards, and performance flows to support implementation across custom AI solutions and enterprise-grade AI software development pipelines.
Introduction
User‑perceived responsiveness in AI systems depends on both compute and network paths. Implementing Industry 5.0 AI and IoT systems requires careful edge-cloud coordination. Mobile, kiosk, factory, branch, and call‑center endpoints experience variable RTT (10–200 ms), bandwidth constraints, and intermittent connectivity. Meanwhile, privacy laws and security policies may require local processing of PII/PHI and residency of certain indices. An edge–cloud co‑design places time‑critical, privacy‑sensitive, and cacheable components at or near the user, and offloads heavy, shared, or global tasks to the cloud-coordinated under explicit SLOs and error budgets.
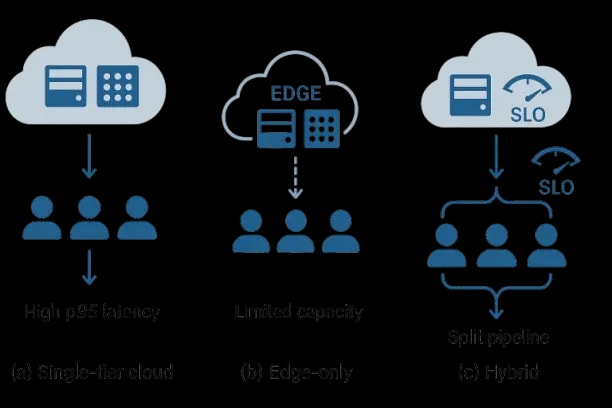
Workload Taxonomy and Latency Budgets
Workload Classes
- -Classifiers/routers: intent, language, safety; target <50–100 ms p95.
- -Extractors: schema‑bound JSON from text/vision; <200–500 ms p95 on typical pages/frames.
- -RAG assistants: streamed token responses; TTFT <150 ms, stable tps >30–60; E2E 1–4 s for short tasks.
- -Agents with tools: additional variance from API calls; guard per‑tool SLOs and budgets.
Latency Budgeting
End‑to‑end latency (L) splits across: network RTT (R_n), edge compute (C_e), cloud compute (C_c), and verification/policies (V). Budget per stage with safety margins and degradation modes.
L = R_n + C_e + R_{ec} + C_c + R_{ce} + V.
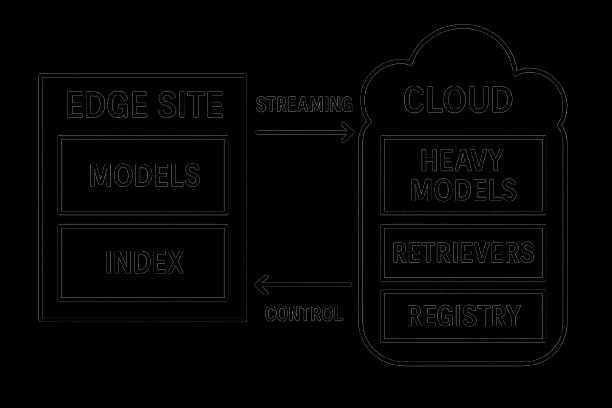
Reference Architecture
Components: client SDK (streaming + caches), edge runtime (NPU/GPU/CPU), edge index for RAG with predictive analytics for operational intelligence, policy. Sophisticated deployments employ multi-agent AI workflows for enterprise automation to orchestrate edge and cloud tasks. & DLP filters, router, verifier, and cloud control plane (model registry, policy engine, evaluator, observability) designed to support scalable custom AI development.
Data paths: request → ingress filters → router → (edge model / cloud model) → verifier → policy engine → output; lineage logged. Building autonomous AI agents for industrial operations often requires edge-cloud partitioning.
Partitioning Strategies
Functional Split
- -At edge: tokenization, language/intent/safety pre‑filters, OCR/light vision, local retrieval, speculative decoding draft, rendering.
- -In cloud: large‑context reasoning, cross‑tenant search, complex tool calls, high‑precision verification.
Model Split
- -Distilled small models at edge for first‑pass routing/extraction.
- -Speculative decoding: edge drafts tokens with a small model; cloud verifies/accepts/rejects (saves TTFT).
- -Mixture‑of‑Experts in cloud with top‑1 fallback under congestion.
Data Split
- -Local indices for hot, private corpora; cloud indices for global or heavy corpora. Consistency via snapshot replication and delta logs.
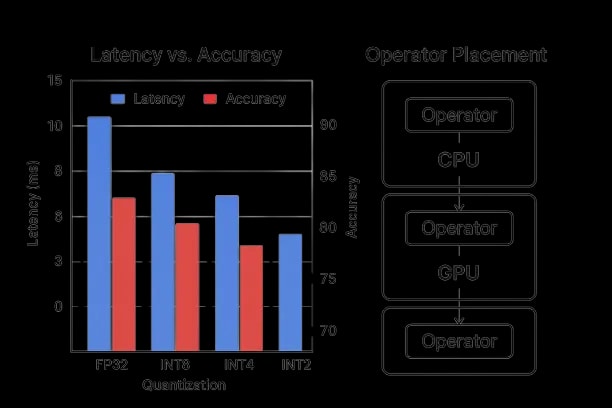
Compression and Hardware Mapping
- -Quantization: 8‑bit/4‑bit weight‑only on edge; dynamic per‑layer precision for hotspots.
- -PEFT adapters: tenant/domain adapters composed on small base models at edge.
- -Pruning & distillation: remove seldom‑used heads/experts; knowledge distill to edge variants.
- -Operator fusion: optimize tokenization/OCR/pre/post on NPUs.
- -KV cache management: pin hot prefixes; windowed attention for long contexts.
Networking and Transport
- -HTTP/2 or gRPC for multiplexed streams; WebSockets for token streaming.
- -Predictive prefetch of retrieval candidates; edge‑side reranking to reduce payload.
- -Congestion‑aware streaming: pace tokens; adaptive chunk sizes; resume on disconnect.
- -TLS session resumption and connection pooling; MTU tuning for cellular links.
Retrieval at the Edge
- -Incremental indexing with tombstones; attested sources; PII token vault on device.
- -Hybrid retrieval (BM25 + small dense model) on edge, with cloud rerank as needed.
- -Freshness SLOs: e.g., <10 min for branch caches; conflict resolution via vector clock.
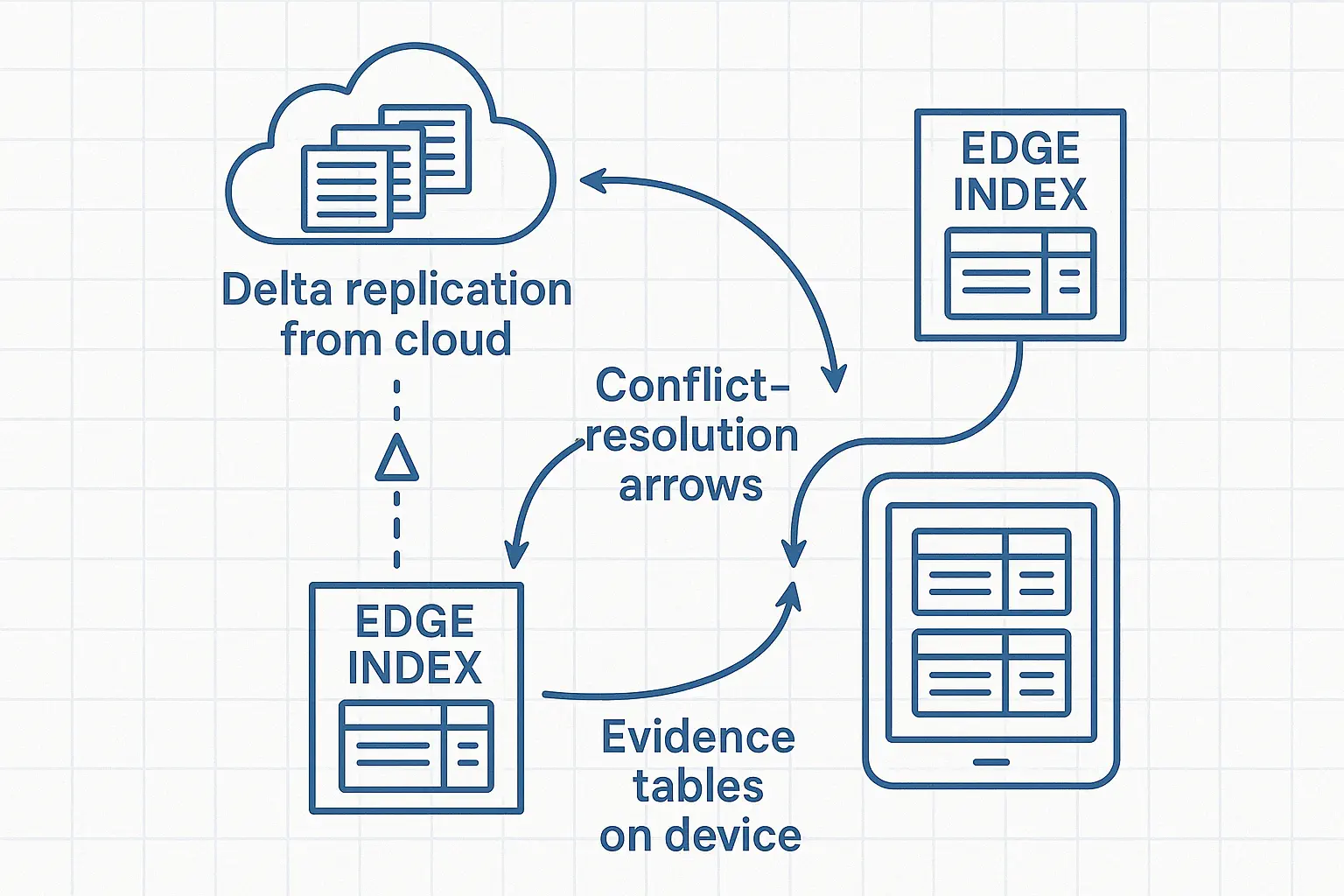
Consistency and State
- -Snapshot + delta logs replicate models, indices, and policies; idempotent apply; detect drift with checksums core mechanisms for robust AI software development.
- -Eventually consistent caches with staleness budgets; critical policies updated with two‑phase commit.
- -Clock and versioning: monotonic counters per site to order events.
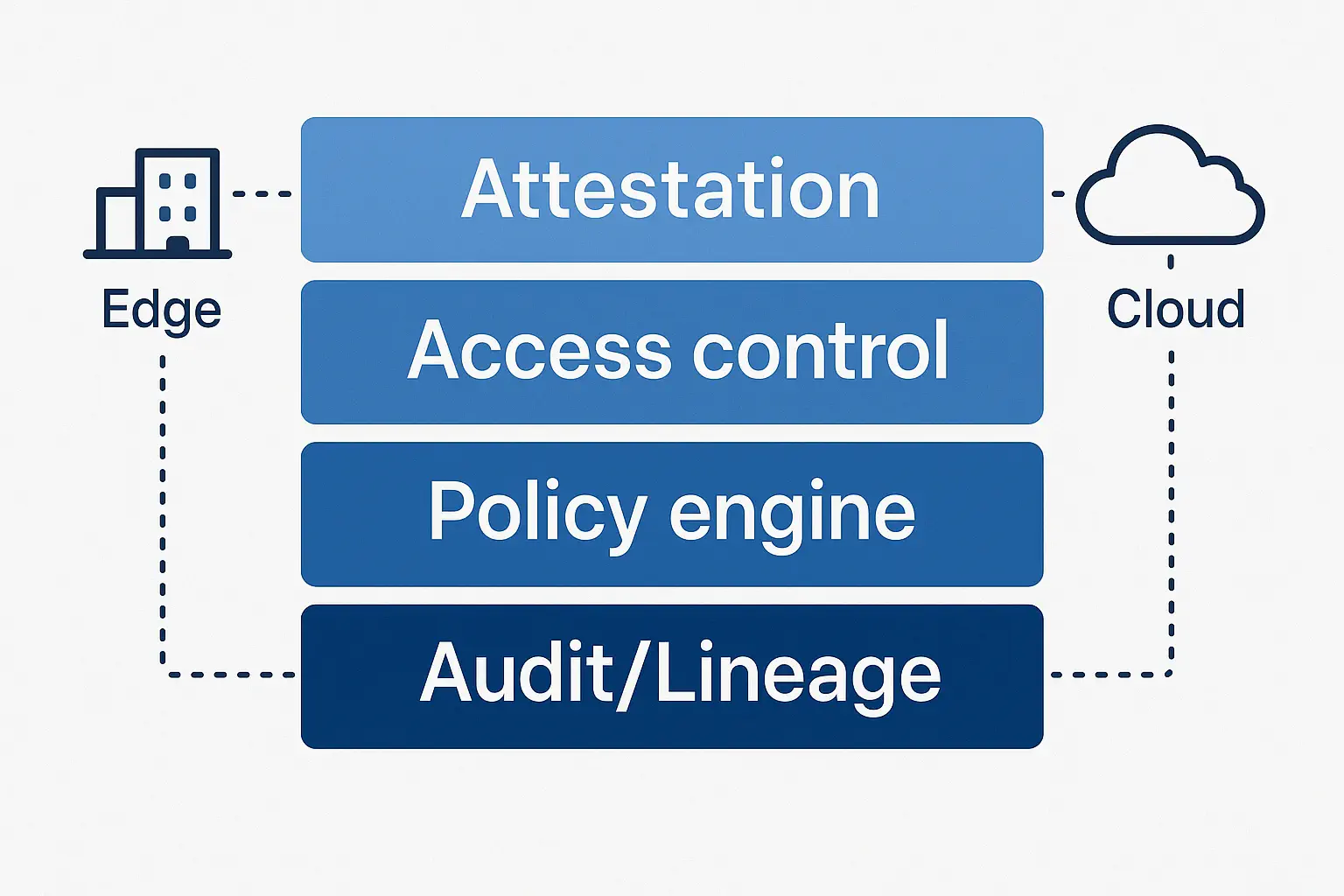
Privacy, Security, and Governance
- -On‑device DLP and redaction; token vault for reversible PII;
- -Isolation: tenant‑scoped stores, per‑site keys, offline‑first logs;
- -Policy‑as‑code with allow/transform/block; evidence‑only mode switch on incidents.
- -Attestation for edge runtime; signed artefacts for models/prompts/policies.
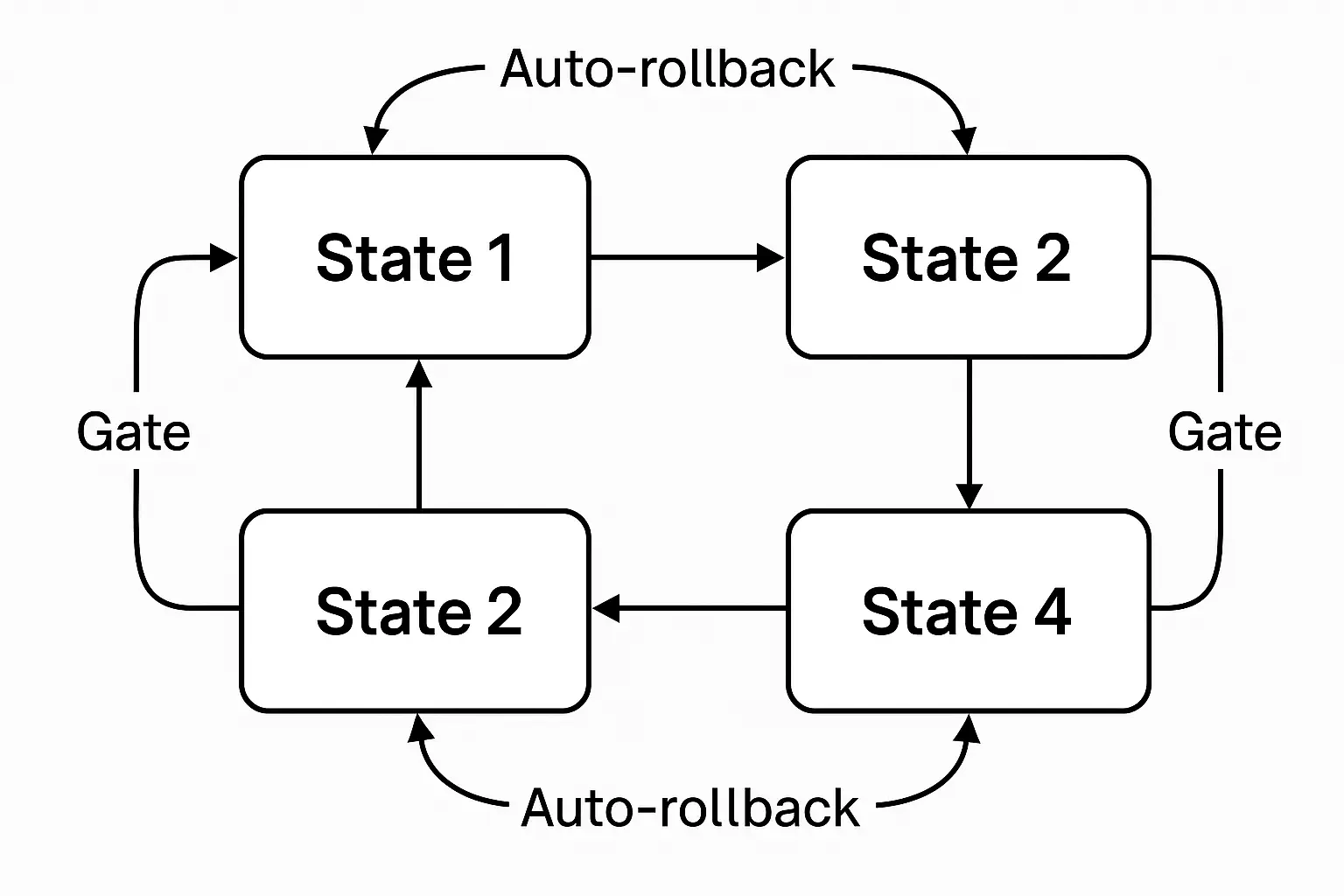
Orchestration and Rollouts
- -Event‑driven state machine: candidate → shadow (mirrored) → canary (1–5%) → A/B → promote/rollback.
- -Bandwidth‑aware updates: prioritize small adapters first; lazy fetch large weights.
- -Safe migrations: run dual stacks; measure regret and wasted work.
Pseudo‑code (Rollout controller):
on model.registered(m):
shadow(edge_sites, m)
if shadow.kpis pass: canary(edge_subset, m)
if canary.safe && kpi_lift: promote_all(m) else rollback(m)
Scheduling and Admission Control
- -Profile routing: pick small/large models and retrieval depth given budgets.
- -Queue shaping: limit high‑cost requests; fast‑lane for premium tiers.
- -Power/thermal‑aware scheduling on mobile/embedded.
- -Dynamic k (documents, experts) and speculative accept ratio tuned by load.
Verification and Safety at the Edge
- -Schema checks for extractors; constrained decoding JSON.
- -Multilingual safety models on edge; abstention thresholds; post‑filters for PII/PHI.
- -Verifier‑driven escalation to cloud when confidence low or policy risk high.
Pseudo‑code (Verifier‑driven escalation): Deploying AI infrastructure inspection systems at the edge requires robust verification.
if !verify(schema|entailment|policy):
escalate_to_cloud()
else publish()
Observability and SLOs
Metrics: TTFT, tokens/sec, p50/p95/p99 latency per stage, cache hit rates (KV/prefix/retrieval/response), violation rate, abstention correctness, queue depths, drop/timeout counts, energy per artifact.
Tracing: prompt versions, model/policy IDs, retrieval doc IDs/spans, tool actions, edge site ID, firmware.
Dashboards: cohort views by site/region/tenant; error‑budget gauges.
Cost and Energy
- -Compute placement to minimize redundant cloud tokens; maximize edge cache reuse.
- -Quantized edge inference reduces energy; off‑peak model/adapter syncs; carbon‑aware routing.
- -CpAA (cost per accepted artifact) with energy adders; report variance as risk.
Evaluation: From Bench to Field
- -Offline: latency simulators with network traces (LTE/5G/Wi‑Fi), accuracy vs. quantization curves, retrieval A/B in replay.
- -Shadow: full edge streaming with mirrored cloud; disagreement sampling for review.
- -Canary: gates on safety/latency; regressions auto‑rollback.
- -A/B: stratify by site/tenant/channel; CUPED variance reduction.
Case Studies
Branch Support Kiosks
Edge classifiers (intent/safety), local RAG index, cloud LLM for escalation. Real-world deployments of AI visual inspection systems for manufacturing showcase edge-cloud benefits. Results: TTFT 90 ms, p95 1.9 s E2E, deflection +8.5%, violations stable.
Factory QA (Vision + Text)
On‑device defect detector + text extractor; cloud for rare defect reasoning. Results: p95 inspection 280 ms; cost −24%; zero P1 incidents after verifier‑gated escalation.
This case study reflects a TRITVA deployment running on PETRAN-managed asset records.
Field Sales Copilot (Mobile)
Speculative decoding at edge; cloud accept/reject; offline cache with conflict resolution. Results: perceived latency −35%, energy −18% per session.
Implementation Blueprint
Edge Runtime API (Pseudo‑Code)
init(models, policies, indices). Following an enterprise AI transformation roadmap helps teams navigate edge-cloud deployment.
serve(request):
x = prefilter(request)
if route_edge(x):
y = small_model(x)
if verify(y): return y
y2 = stream_to_cloud(x)
return verify_and_publish(y2)
Sync Protocol (Pseudo‑Code)
periodic:
pull(snapshot)
while deltas:
apply(delta); verify_hash()
attest(runtime); rotate_keys()
Safety Policy Example (YAML)
policy_id: safe-answers-v3
allow:
- grounded_claims
transform:
- redact_pii
block:
- speculative_financial_promises
abstain_thresholds:
entailment: 0.85
Checklists
Readiness
- -Edge hardware inventory and perf baselines.
- -Latency budgets per workload; degradation modes defined.
- -Local indices and token vault; DLP at ingress.
- -Quantized/PEFT edge models; speculative decoding configured.
Operations
- -Event‑driven rollouts with auto‑rollback.
- -Cohort dashboards by site/tenant.
- -Burn‑rate alerts for safety/latency/cost.
- -Sync/attestation runbooks.
Security & Governance
- -Tenant isolation and keys; egress controls.
- -Policy‑as‑code with tests; evidence‑only mode switch.
- -Tamper‑evident logs; audit packs.
Open Questions and Future Directions
- -End‑to‑end speculative pipelines (multi‑stage drafting across devices).
- -Causal routing that exploits live network/energy signals.
- -Proof‑carrying artifacts for models/prompts/policies across edge sites.
- -Unified memory layers (semantic + KV + response) with privacy‑preserving sync.
Conclusion
Edge–cloud co‑design transforms custom AI from a high‑latency monolith into a responsive, privacy‑aware, and cost‑efficient platform. By partitioning computation, shaping networks, enforcing policy‑as‑code, and operating with event‑driven rollouts and rigorous observability, teams can meet strict SLOs without sacrificing safety or governance. The patterns, pseudo‑code, and dashboards provided here form a practical blueprint for deploying low‑latency custom AI at scale.
Ombrulla's TRITVA and PETRAN platforms implement these patterns across production deployments in oil and gas, manufacturing, and infrastructure inspection.
References
- Caballero, J., Płociniczak, Ł., & Sadarangani, K. (2024). Existence and uniqueness of solutions in the Lipschitz space of a functional equation and its application to the behavior of the paradise fish. Applied Mathematics and Computation, 477, 128798.[arxiv]
- Miao, X., Oliaro, G., Zhang, Z., Cheng, X., Wang, Z., Wong, R. Y. Y., ... & Jia, Z. (2023). Specinfer: Accelerating generative llm serving with speculative inference and token tree verification. arXiv preprint arXiv:2305.09781, 1(2), 4.[cmu]
- Khan, M. J., Fang, B., Cimino, G., Cirillo, S., Yang, L., & Zhao, D. (2024, July). Privacy-preserving artificial intelligence on edge devices: a homomorphic encryption approach. In 2024 IEEE International Conference on Web Services (ICWS) (pp. 395-405). IEEE.[researchgate]
- Blalock, D., Gonzalez Ortiz, J. J., Frankle, J., & Guttag, J. (2020). What is the state of neural network pruning?. Proceedings of machine learning and systems, 2, 129-146.[mlsys]
- Shi, W., Cao, J., Zhang, Q., Li, Y., & Xu, L. (2016). Edge computing: Vision and challenges. IEEE internet of things journal, 3(5), 637-646.[researchgate]