Long‑Context Custom AI: Retrieval, Memory, and Compression
Abstract
As organizations move AI assistants and copilots from demos to mission-critical workflows, they run into practical limits. Context windows are too small, latency grows, and costs spike. Long-context models (LCMs) promise windows from thousands up to millions of tokens, but using them naively doesn’t scale. Attention becomes too expensive without sparsity, model quality often drops beyond a few tens of thousands of tokens, and compliance teams still need verifiable grounding, not just longer prompts.
This white paper takes a systems view on custom AI solutions for enterprise-scale intelligent systems and custom ai development for long-context use cases. We show how to combine retrieval, memory architectures, and compression to build reliable ai software that can handle large, evolving information spaces.
We define a clear memory model with four types: ephemeral, working, episodic, and semantic. We survey attention variants and external memory schemes, then outline practical compression strategies such as map-reduce style summarization, lossy and lossless token transforms, and learned selectors to keep context both manageable and useful.
Finally, we propose reference architectures for ai software development teams, along with evaluation methods and SLOs that cover reliability, quality, safety, and cost. The paper is designed as a practical guide for building long-context ai solutions, and includes prompts for images and graphs to help communicate concepts to stakeholders and implementation teams.
Introduction
Applications like due‑diligence review, research assistants, eDiscovery, technical support, and code intelligence require reasoning over hundreds of documents, long threads, or weeks of conversation history. Extending token windows seems like the obvious fix, yet product teams face three realities:
1. Performance drift: quality often degrades beyond 32–64k tokens due to sparse signal, positional drift, and attention confusion.
2. Latency and cost: quadratic or high‑constant‑factor attention makes naive long prompts slow and expensive; streaming helps UX but not compute.
3. Governance: long prompts accumulate sensitive data and stale facts; verifiable citations and retention policies become critical.
We argue for a triad strategy: (a) retrieve the right context, (b) remember what matters over time, and (c) compress aggressively while preserving task‑relevant fidelity. This approach leverages generative AI systems and enterprise AI innovation to build scalable, intelligent systems. We provide concrete designs, metrics, and guardrails.

Background and Concepts
Context, Attention, and KV Caches
- -Context window: maximum tokens a model conditions on. Large windows strain positional encodings and increase computation in custom AI development ent for enterprise knowledge systems.
- -Attention complexity: naive self‑attention is O(n²); sparse patterns (sliding window, dilated, block‑global) reduce cost; FlashAttention‑class kernels improve constants.
- -KV cache: in auto‑regressive decoding, caches Key/Value tensors; prefix caching amortizes recurring context across turns.
Memory Types (Functional)
- -Ephemeral memory: per‑turn token context; discarded after reply.
- -Working memory: short‑horizon session state (recent steps, tool outputs); minutes to hours.
- -Episodic memory: per‑user or per‑project events (threads, tasks); weeks to months.
- -Semantic memory: durable knowledge distilled from episodes (facts, embeddings, graphs); months+.
Retrieval and Grounding
- -Hybrid retrieval: keyword (BM25) + dense embeddings; reranking (bi‑/cross‑encoder) and multi‑query reformulation.
- -Cite‑before‑say: enforce evidence tables; refuse when no support.
- -Temporal freshness: index lag and recency filters; dedup and canonicalization.
Compression
- -Lossless: dedup, whitespace/punctuation folding, boilerplate stripping, table serialization.
- -Lossy (task‑aware): extractive summarization, key‑sentence selection, structural pruning, schema‑aware compaction (JSON→CSV), diagram→text descriptions.
- -Learned: selector models (token/segment scoring), state summarizers, and latents.
Reference Architecture for Long‑Context Systems
High‑Level Components
1. Content Ingest: parsers for PDFs/HTML/Office; OCR; normalisers; de‑dup; entity linking.
2. Indexing: chunking (semantic and structural), embeddings, metadata, graph edges, recurrence counters.
3. Retrieval: hybrid search; multi‑hop expansion; reranking; cohort filters.
4. Memory Services: episodic log store; semantic vector store/graph; summarization distillers; user/project profiles.
5. Compression Services: lossy/lossless pipelines; selector models; map‑reduce summarizers.
6. Orchestrator/Planner: chooses tools, prompts, decoding profiles; enforces budgets.
7. Verifier/Critic: schema, policy, entailment; evidence checks; cost & safety guards.
8. Observation: traces; quality and efficiency metrics; error budgets.
Control Loops and Budgets
- -Token budget: max tokens allocated among retrieved passages, memory summaries, and user input. Optimized per task via bandits or heuristics.
- -Latency budget: per‑stage p95 targets; early exits when exceeded.
- -Cost budget: per‑request or per‑day caps; degrade to smaller models or coarser summaries.
KV and Prompt Reuse
- -Prefix reuse: pin static instructions and stable memory into cached prefixes; inject only deltas.
- -Rolling windows: evict low‑utility spans by recency and selector scores; maintain evidence pins that persist across turns.
Retrieval at Scale for Long Context
Chunking and Canonicalization
- -Semantic chunking using headings, lists, and tables; overlap tuning to preserve coherence; ID stability for citations in custom AI development workflows.
- -Normalize variants (whitespace, fonts, bullets); deduplicate by content hash + fuzzy similarity.
Query Reformulation
- -Self‑ask/multi‑query: generate diverse sub‑queries; decompose complex tasks (who/what/when/where constraints).
- -Entity/temporal expansion: add aliases, time filters, jurisdiction filters.
Reranking Cascades
- -BM25 → bi‑encoder → cross‑encoder cascade; early terminate when confidence saturates; teach rerankers with click/approval signals.
Freshness and Coverage SLIs
- -Indexing lag p95 ≤ 15 min; freshness coverage ≥ 95% from ≤ 24h content; collection coverage across sources.
Memory Design: What to Keep, How to Keep It
Summarization as Distillation
- -Custom AI development ent for enterprise knowledge systems uses the Map → Reduce → Refine pattern: (a) segment episodes, (b) local extractive summaries with evidence links, (c) global synthesis with provenance.
- -Multi‑view summaries: task‑conditioned views (e.g., risk, compliance, decisions), persona‑conditioned tone.
State vs. Narrative
- -State memory: structured facts (key‑value, JSON) for quick hydration; great for preferences, counters, milestones.
- -Narrative memory: short textual summaries with citations; use for rationales and context.
Memory Stores
- -Vector store for semantic recall; graph for entities and relations; document store for provenance.
- -Eviction policies by recency, usefulness, confidence, and risk.

Personalization and Privacy
- -Respect purpose limitation; tag memory items with scope (project, tenant) and TTL; implement right‑to‑erasure.
- -Store only non‑sensitive derived features when possible; encrypt at rest and in transit.
Compression Techniques: From Tokens to Signals
Lossless Pipeline
- -Whitespace & punctuation folding, markdown to plain text, tables to CSV, code blocks normalized, boilerplate filters.
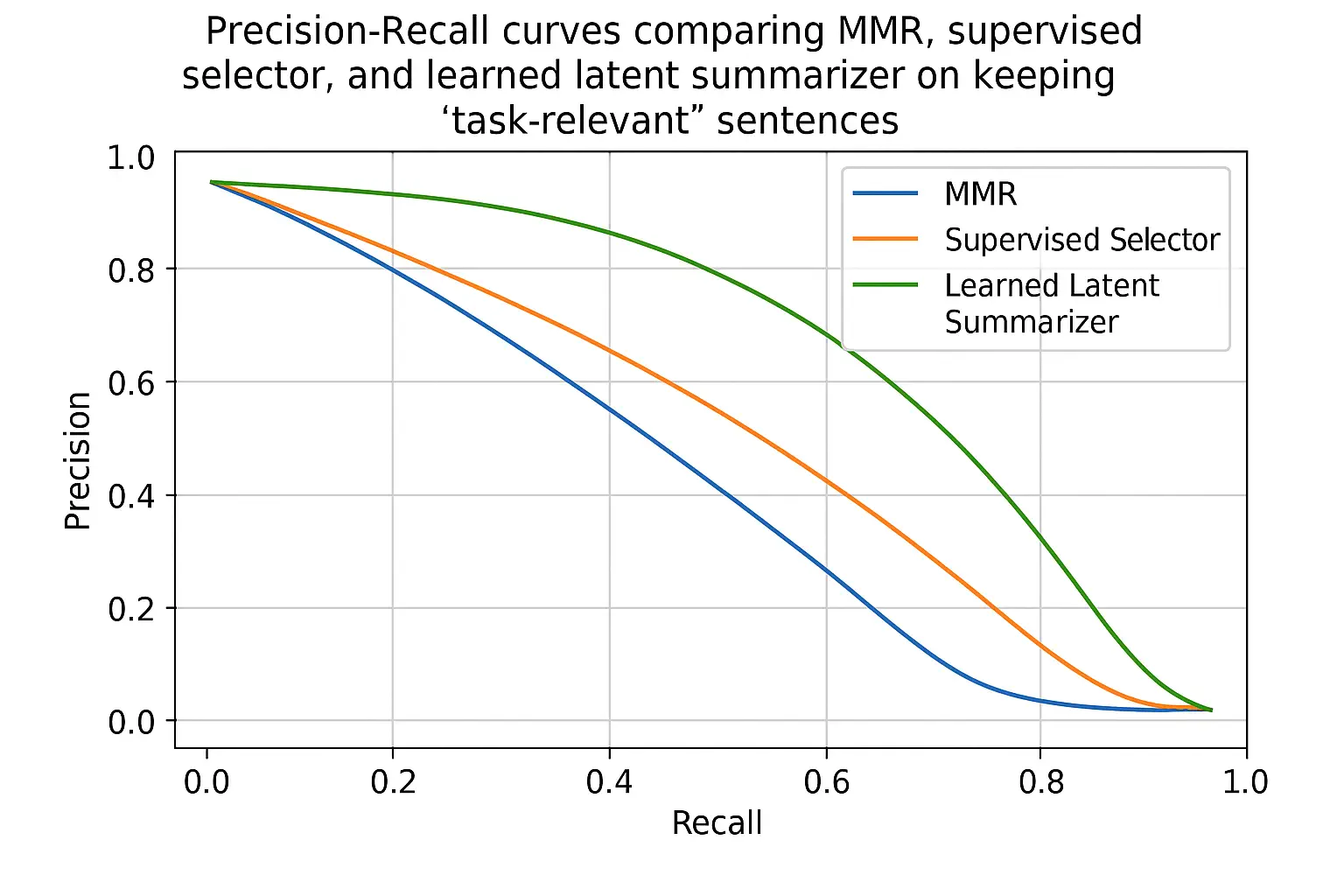
Extractive Selectors
- -Sentence/paragraph scoring via Maximal Marginal Relevance (MMR), supervised selectors (bi‑encoders), or reinforcement for utility.
- -Citation‑first selection: prefer spans with strong evidence and clear attributions.
Abstractive Compression
- -Budgeted summarization: optimize for target token length; preserve entities/dates/amounts with constrained decoding.
- -Style conditioning: terse (bullet), legal (shall/must), executive (headlines), or developer (code+comments).
Learned Latent Compression
- -Encode documents to latent codes; decode on demand; useful for giant corpora with repeated structures.
Decoding and Control for Long Context
- -Use constrained decoding for schemas (JSON/CSV) and citations; enforce evidence‑only mode during incidents.
- -Temperature and top‑p tuned per profile to avoid drift; contrastive decoding to prefer grounded tokens.
- -Abstention on low confidence or missing evidence; escalate to human.
Evaluation: Long‑Context Quality, Reliability, and Cost
Datasets and Cohorts
- -Build needle‑in‑a‑haystack tasks (NIAH) with passage positions; haystack‑of‑needles with multiple relevant spans; temporal drift sets; conversation chains.
- -Cohorts by document type, age, scan quality, language, and sensitivity.
Metrics
- -Retrieval: Recall@k, nDCG, Coverage, Freshness.
- -Answer quality: exact match/F1 for extractive tasks; rubric for summaries (coverage, correctness, specificity); citation precision/recall, evidence coverage.
- -Long‑context robustness: performance vs. context length (10k → 200k); positional drift tests. AI analytics for enterprise intelligence helps measure these metrics effectively.
- -Efficiency: p50/p95/p99 latency (retrieve, rerank, generate), token burn, cache hit rates.
- -Reliability: availability, error rate, SLO burn‑rate; abstention correctness.
- -Safety: policy violations, PII leakage, jailbreak susceptibility.
Statistical Design
- -Define MDE (e.g., +3 pts macro‑F1); compute power per cohort; bootstrap CIs; BH corrections across metrics; sequential tests for canarying.

SLOs, SLAs, and Error Budgets for Long Context
- -Latency SLOs: p95 ≤ 4s for extraction; ≤ 6s for summaries at 8 passages; degradation modes when budgets exceed.
- -Evidence coverage SLO: ≥ 98% claims cited; faithfulness ≥ 95% by entailment checks.
- -Indexing lag SLO: p95 ≤ 15 min; freshness coverage ≥ 95%.
- -Cost SLO: p95 cost per item within cap; auto‑switch to tighter compression.
Security, Privacy, and Governance
- -Data minimization in memory; encrypt and sign artifacts; maintain audit trails linking claims to sources and versions.
- -Access control at index and query time; tenant isolation; retention policies with TTL and purpose binding.
- -Incident playbooks: leakage, poisoning, retrieval collapse; enforce evidence‑only mode and increased HITL.
Implementation Blueprint (Pseudo‑Code)
struct Budget { tokens_total, tokens_user, tokens_retrieval, tokens_memory }
struct Evidence { doc_id, span, score }
function plan(request):
profile <- select_profile(request.intent)
budget <- allocate_tokens(profile, request)
return profile, budget
function retrieve_and_compress(query, budget):
q <- reformulate(query)
cands <- retrieve_hybrid(q, k=200)
reranked <- cascade_rerank(cands)
selected <- select_top(reranked, k=budget.passages)
extracts <- extractive_select(selected, budget.tokens_retrieval)
memory <- hydrate_memory(query, budget.tokens_memory)
return compress(extracts + memory, budget)
function generate_with_evidence(context, profile):
out <- model.generate(prompt=profile.template, context=context,
constraints=profile.constraints, decoding=profile.decoding)
if missing_citations(out) or low_confidence(out):
return refuse_or_escalate()
return out
function conversation_turn(request):
profile, budget <- plan(request)
context <- retrieve_and_compress(request.text, budget)
reply <- generate_with_evidence(context, profile)
update_memories(request, reply, evidence_from(reply))
return reply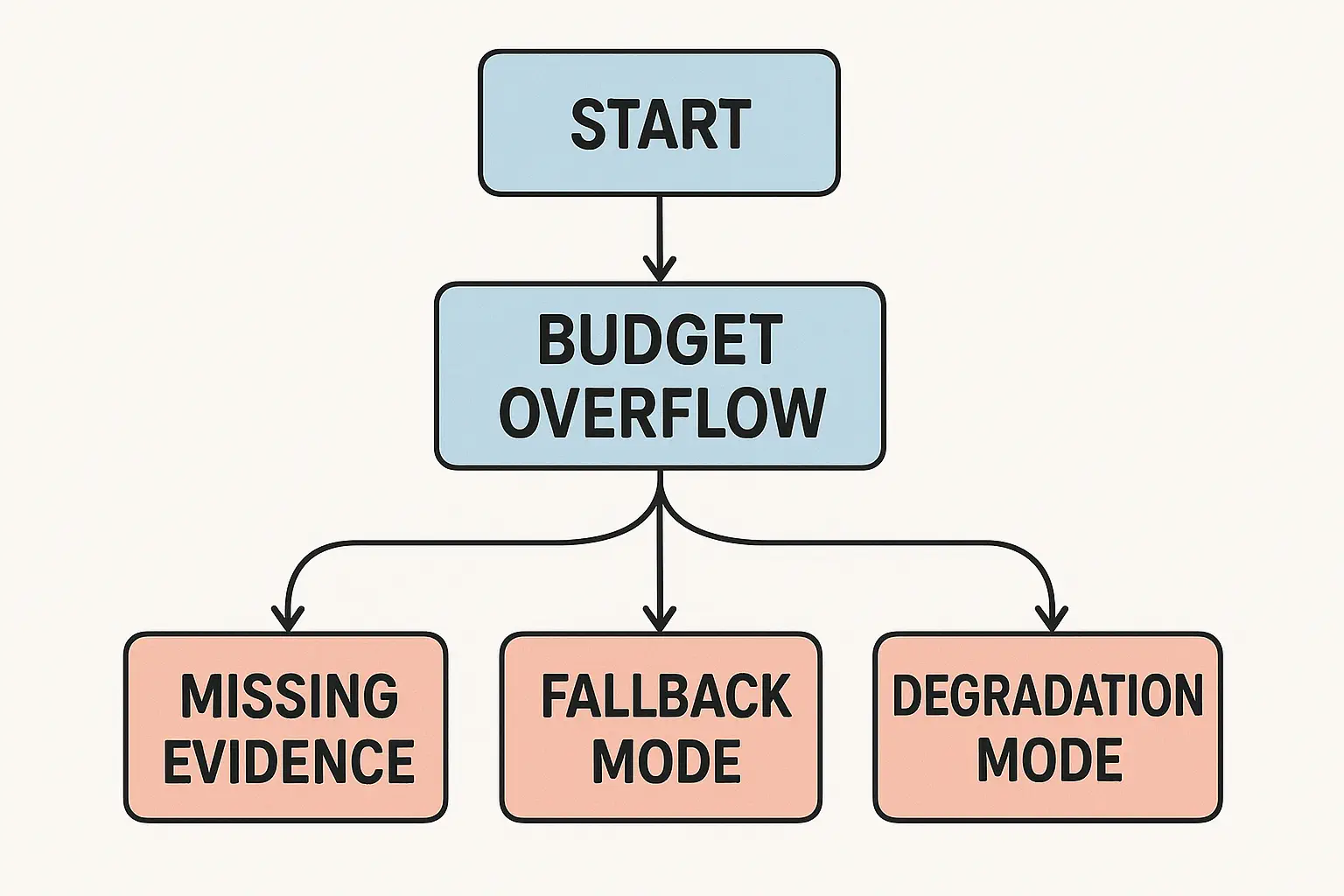
Patterns and Anti‑Patterns
Patterns
- -Cite‑before‑say with refusal paths; schema‑bound outputs.
- -Bandit token allocator that learns optimal splits among retrieval/memory/user input.
- -KV prefix pinning for stable instructions; rolling window managed by selectors.
- -Hybrid retrieval with reranking and freshness SLIs; cohort‑aware evaluation.
Anti‑Patterns
- -Prompt hoarding: dumping entire corpora into the prompt; skyrocketing cost and degraded quality.
- -Vector‑only myopia: ignoring keyword filters and metadata constraints.
- -Stale memories: no TTLs, leading to outdated or biased summaries.
- -Unverifiable synthesis: citations as decoration without entailment checks.
Case Studies
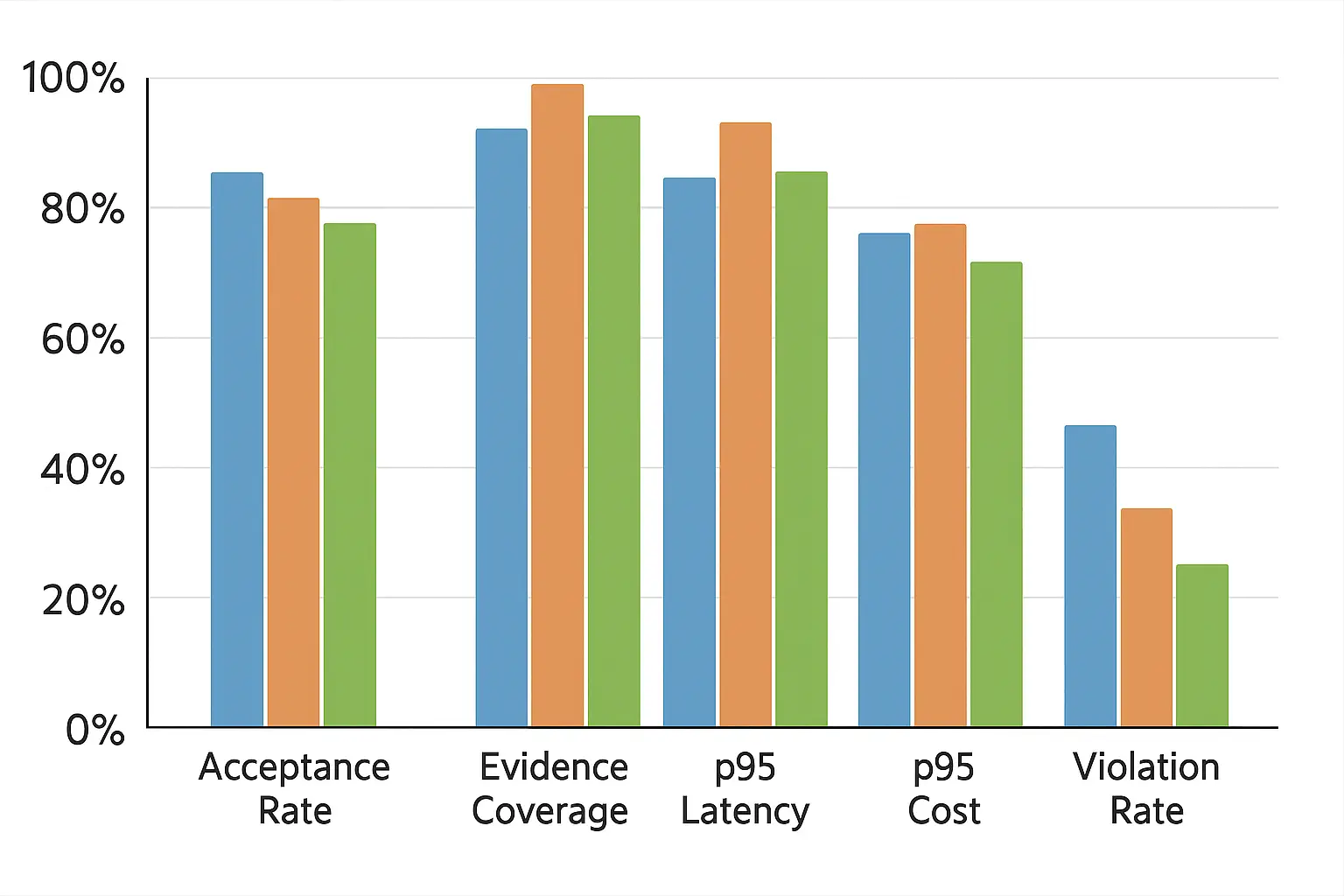
eDiscovery & Investigations
-Problem:
tens of thousands of emails and attachments; long threads; legal standards for evidence.
-Approach:
hybrid retrieval + cross‑encoder reranking; extractive selectors; map‑reduce summaries with provenance; evidence‑only fallback; per‑custodian memories. Similar techniques are used in AI visual inspection systems for industrial automation.
-Outcome:
reviewer hours −35%; evidence coverage 99.3%; p95 latency 4.2s at 10 passages.
Technical Support Copilot
-Problem:
long ticket histories; mixed logs; policy constraints.
-Approach:
working memory for device state; semantic memory of fixes; compression to structured steps; bandit token allocator tuned for deflection. This mirrors the approach used in AI-powered asset performance management systems.
-Outcome:
first‑contact resolution +17%; p95 cost/item −28%; violation rate <0.1%.
Code Intelligence
-Problem:
multi‑repo, multi‑language codebases; long files and dependency graphs.
-Approach:
structure‑aware chunking (AST); graph retrieval on imports; extractive slices; constrained generation (patches/tests); rolling KV with recent edits. This leverages autonomous AI agents for enterprise workflows to automate code analysis.
-Outcome:
task success +22 pts; latency within SLOs; fewer hallucinated APIs.
Checklists
Readiness
- -Corpus inventory and de‑duplication complete; PII redaction rules in place.
- -Hybrid retrieval and reranking operational; freshness monitors.
- -Token/latency/cost budgets defined; degradation modes documented.
Quality & Safety
- -Evidence coverage and faithfulness metrics wired; refusal threshold set.
- -Long‑context robustness tests built (NIAH, positional drift).
- -Cohort‑aware dashboards with power‑calculated sample sizes.
Operations
- -KV prefix caching configured; rolling window selectors tuned.
- -Memory TTLs and scopes defined; erase and export pathways tested.
- -Burn‑rate alerts for latency, cost, and safety; runbooks rehearsed.
Future Directions
- -Hierarchical memory‑transformer hybrids with certified bounds on information retention.
- -Executable traces: program‑of‑thought where intermediate steps are verifiable and cacheable.
- -Neural compression with guarantees: rate–distortion objectives tuned to task‑level fidelity.
- -Cross‑session personalization with privacy budgets and federated updates.
Conclusion
Long context is not a license to stuff more tokens-it is a design problem across retrieval, memory, and compression under reliability, safety, and cost constraints. By embracing hybrid retrieval, disciplined memory with TTLs and provenance, and aggressive but principled compression, teams can deliver systems that reason over large corpora reliably and verifiably. The architectures, metrics, and checklists here aim to accelerate that journey from demo to durable production.
References
- Beltagy, I., Peters, M. E., & Cohan, A. (2020). Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150.[arxiv]
- Zaheer, M., Guruganesh, G., Dubey, K. A., Ainslie, J., Alberti, C., Ontanon, S., ... & Ahmed, A. (2020). Big bird: Transformers for longer sequences. Advances in neural information processing systems, 33, 17283-17297.[neurips]
- Dao, T., Fu, D., Ermon, S., Rudra, A., & Ré, C. (2022). Flashattention: Fast and memory-efficient exact attention with io-awareness. Advances in neural information processing systems, 35, 16344-16359.[neurips]
- Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., ... & Kiela, D. (2020). Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems, 33, 9459-9474.[neurips]
- Reimers, N., & Gurevych, I. (2019). Sentence-bert: Sentence embeddings using siamese bert-networks. arXiv preprint arXiv:1908.10084.[arxiv]