

Failure Cause #1 - The Data Problem Nobody Admits
"We had four years of sensor data. The problem was that three years of it was meaningless." - Operations Director, European Petrochemical Plant (anonymised)
The most common cause of industrial AI pilot failure is also the least glamorous, the most predictable, and the most consistently underestimated: data quality. Not data quantity; quantity is rarely the issue. Quality, labelling, accessibility, and operational context are almost always the issue.
Research by IBM published in 2022 estimated that poor data quality costs the US economy approximately $3.1 trillion annually. In industrial environments, the problem is structurally worse than in most other sectors because of how operational technology (OT) data is generated, stored, and accessed.
The OT Data Reality
Industrial facilities generate enormous volumes of data; a modern offshore oil platform may have 20,000 to 40,000 sensor tags generating readings at one-second intervals. A large automotive assembly plant may produce gigabytes of quality inspection data per shift. But the characteristics of that data are frequently incompatible with what AI models require:
- - Sparse defect labellingIn AI quality inspection applications, defects are rare events in otherwise normal data streams. A production line running at 99.5% quality yield generates thousands of 'normal' observations for every single defect. AI models trained on this imbalanced data learn to predict 'normal' with extremely high accuracy, while completely failing to detect the defects that matter.
- - Inconsistent timestamps and sampling ratesOT data from different systems, PLCs, SCADA historians, DCS, manual inspection logs - is rarely synchronised. AI models that require aligned multi-source data inputs fail at the data fusion stage.
- - Unlabelled historical dataYears of sensor data stored in process historians are entirely unlabelled. Before it can be used for supervised AI training, a domain expert must label it - a process that requires hundreds of engineering hours and is frequently not budgeted.
- - Missing contextRaw sensor readings without process context are often uninterpretable. A vibration anomaly on a pump might indicate bearing wear, or it might indicate a planned high-load operation that the AI model interprets as an anomaly because it has never been told the difference.
| Data Challenge | % of Industrial AI Pilots Affected | Source |
|---|---|---|
| Insufficient labelled training data | 71% | Gartner AI in Manufacturing Survey, 2023 |
| Poor OT data quality/sensor drift | 64% | McKinsey IIoT Analysis, 2023 |
| Data accessibility/silo barriers | 58% | IDC Industrial AI Survey, 2024 |
| Insufficient data volume for rare events | 53% | Deloitte AI Adoption Report, 2023 |
The data problem is compounded by a common pilot design failure: using the best available data for the pilot, data that has been cleaned, labelled, and curated specifically for the demonstration - while ignoring the fact that the production AI system will have to work with raw, uncurated, real-time data streams. The pilot looks impressive because it is working on exceptional data. Production fails because it is confronted with operational reality.
What Successful Deployments Do Differently
Organisations that successfully scale industrial AI past the pilot stage invest in data engineering before AI engineering. They establish OT data pipelines, implement sensor data quality monitoring, build labelling programmes as an operational function (not a one-time project), and run data readiness assessments before a single AI model is trained. Data infrastructure is not a pre-requisite they mention in a slide, it is a funded workstream they treat as the most important phase of the programme.
Failure Cause #2 - The Pilot Trap: Optimised to Impress, Not to Scale
"The demo environment was perfect. The real environment had 47 different edge cases the model had never seen." - Operations Director, European Petrochemical Plant (anonymised)
The industrial AI pilot trap is one of the industry's worst-kept secrets: proofs of concept are structurally designed to succeed in controlled conditions and structurally unequipped to handle production complexity. It is not that anyone deliberately engineers a misleading demonstration. It is that the incentives and constraints of a pilot programme create a systematic bias toward controlled-environment performance.
Consider the typical industrial AI pilot structure: a vendor or internal AI team selects the best-quality data from a specific time period, defines a narrow use case with clear boundaries, deploys to a single asset or production line, allocates dedicated AI engineering support, and measures performance against a hand-picked success metric. The pilot runs for eight to twelve weeks. Results look strong. The executive presentation is persuasive. And then the decision is made to scale.
Scaling means: all the data, from all the assets, from all time periods, with all the operational variability, without dedicated AI engineering support, integrated with all the legacy systems that were excluded from the pilot scope. And the model falls apart.
The Pilot-to-Production Gap: What Changes
| Variable | In the Pilot | In Production |
|---|---|---|
| Data quality | Curated, cleaned, complete | Raw, inconsistent, sometimes missing |
| Use case scope | Single asset, defined conditions | Fleet-wide, all operating modes |
| Edge cases | Excluded or manually handled | Constant and unpredictable |
| AI engineering support | Full-time data science team | Shared resource, often withdrawn |
| Integration complexity | Manual data feeds or mock API | Full OT/IT integration required |
| Model drift management | Not required - static dataset | Continuous monitoring, retraining cycles |
| Business process change | Inspector/operator aware and engaged | Entire workforce adoption required |
A 2023 analysis by Deloitte of 300 industrial AI programmes found that 67% of the organisations that described their pilot as 'successful' could not define what 'success' would look like at production scale before beginning the pilot. The absence of a production readiness definition at pilot design stage is one of the most reliable predictors of eventual programme failure.
What Successful Deployments Do Differently
The organisations that successfully bridge the pilot-to-production gap design their pilots to mimic production conditions from day one. They deliberately include dirty data, edge cases, and system integration requirements in the pilot scope. They define production success criteria - precision rate, recall rate, work order reduction, downtime savings before the pilot launches, not after. And they treat the pilot as phase one of a production deployment, not as a demonstration event.

Failure Cause #3 - The Organisational Immune System
"The AI said stop the machine. The operator kept it running because he had thirty years of experience and did not trust an algorithm." - Plant Manager, German Automotive Supplier (anonymised)
Industrial organisations have a remarkable capacity for rejecting change. Not out of irrationality, but out of deep experience with change programmes that promised transformation and delivered disruption. The workforce in a large manufacturing plant or oil refinery has typically survived multiple waves of ERP implementation, digital transformation initiatives, and technology-led restructuring. They have learned, empirically, that new technology systems often create more work before they reduce it, and that their jobs may be at risk if the technology succeeds.
A 2024 PwC survey of industrial operations leaders found that 'employee resistance and change management failure' was cited as a top-three cause of AI programme failure by 61% of respondents. Yet in the same survey, only 28% of organisations reported having a dedicated change management workstream in their AI pilot programme. The gap between the recognised importance of change management and the actual investment in it is one of the most consistent findings across all industrial AI failure research.
Four Manifestations of the Organisational Immune Response
- - Passive non-adoption: Operators and inspectors use the AI system during the assessment period and revert to their previous methods as soon as oversight is reduced. The system is technically deployed but operationally ignored.
- - Active circumvention: Experienced workers find ways to override, bypass, or discredit the AI system's outputs when they conflict with their own judgment. In quality inspection, this might mean overriding AI defect classifications and marking findings as false positives.
- - Middle management blocking: Supervisors and plant managers who were not involved in the AI pilot design may see AI-generated insights as a threat to their authority or a challenge to established process ownership. They do not actively oppose the system - they simply do not champion it.
- - Trust collapse after the first false alarm: A single high-profile AI false positive - the system flagging a shutdown that was not warranted or triggering an unnecessary maintenance call can permanently damage workforce trust in the system across an entire facility.
What makes the organisational immune system particularly dangerous for AI programmes is that it is invisible in a pilot. During a proof of concept, the team working with the AI system is typically the most engaged, most digitally literate, and most change-willing subset of the workforce. They are advocates. They are curious. They make the system look better than it will perform at scale.
What Successful Deployments Do Differently
Organisations that overcome the organisational immune system do three things that struggling organisations consistently skip: they involve frontline workers in AI model design and validation (not just testing); they establish an AI change champion network within the operational workforce before deployment; and they celebrate AI-operator collaboration stories rather than AI-replaces-operator narratives. The most successful industrial AI deployments position AI as a tool that makes the experienced worker more effective - not a system that makes experienced workers redundant.
Failure Cause #4 - Integration Debt: When AI Cannot Talk to the Factory
"We had a brilliant AI model. And it sat on a laptop in the control room because nobody could get the data out of the historian." - Reliability Engineer, Middle East Refinery (anonymised)
Industrial AI does not fail in a vacuum. It fails at the interface between the AI layer and the operational technology environment it is supposed to serve. This interface - the integration between AI systems and the legacy OT/IT infrastructure of an industrial facility - is the location where more AI pilot value is destroyed than anywhere else.
The integration challenge in industrial AI is structurally different from the integration challenges of enterprise IT projects. Enterprise systems typically run on standardised protocols, documented APIs, and modern data schemas. Industrial OT environments are characterised by legacy PLCs running proprietary communication protocols from the 1990s, SCADA systems that were never designed to expose data to external applications, process historians with siloed, tag-based data architectures, and physical security-driven network air gaps that prevent direct connectivity between OT and IT systems.
The Five Integration Failure Modes
- - Protocol incompatibility: AI systems designed to consume REST APIs cannot directly communicate with OPC-DA, Modbus, or proprietary DCS communication layers without a middleware translation layer that was not in the pilot scope.
- - Latency mismatch: AI models designed for real-time inference require data in milliseconds. Process historians typically batch data at minute or hour intervals. The AI model that worked with batch data in the pilot fails in real-time operational contexts.
- - Network segmentation: IT/OT network separation - essential for cybersecurity - prevents the direct data flows that the AI system requires. Bridging this gap requires network architecture changes that involve IT security, OT engineering, and operations leadership - a cross-functional approval process that typically takes six to eighteen months.
- - ERP / CMMS handshake failure: AI-generated maintenance recommendations are only valuable if they create work orders in the CMMS. Building this integration - especially into legacy Maximo or SAP PM environments - requires SAP development resources that are rarely scoped into AI pilot budgets.
- - Model output format incompatibility: AI models output probability scores, confidence intervals, and classification labels. Maintenance systems expect predefined work order types, priority codes, and cost centres. The translation layer between AI model output and operational system input is frequently underestimated or absent.
A 2024 analysis by the Manufacturing Leadership Council found that integration complexity was cited as the primary scaling barrier by 54% of manufacturing AI leaders who had successfully built and validated an AI model but could not deploy it operationally. The model was ready. The factory was not.
What Successful Deployments Do Differently
Organisations that solve the integration challenge treat it as a parallel workstream, not a post-pilot activity. They engage OT/IT integration architects in the pilot design phase, select AI platforms with certified OPC-UA, MQTT, and REST API connectors for their specific SCADA and historian environments, and build the ERP/CMMS integration as part of the pilot deliverable - not as a future-phase activity. Integration that is left for 'after the pilot proves the value' is integration that never gets funded.
Failure Cause #5 - The ROI Illusion: Measuring the Wrong Things
"The pilot dashboard showed 94% accuracy. The business case showed zero cost savings. We had optimised for the metric that impressed the data scientists, not the one that mattered to the CFO." - Head of Digital, Global Energy Company (anonymised)
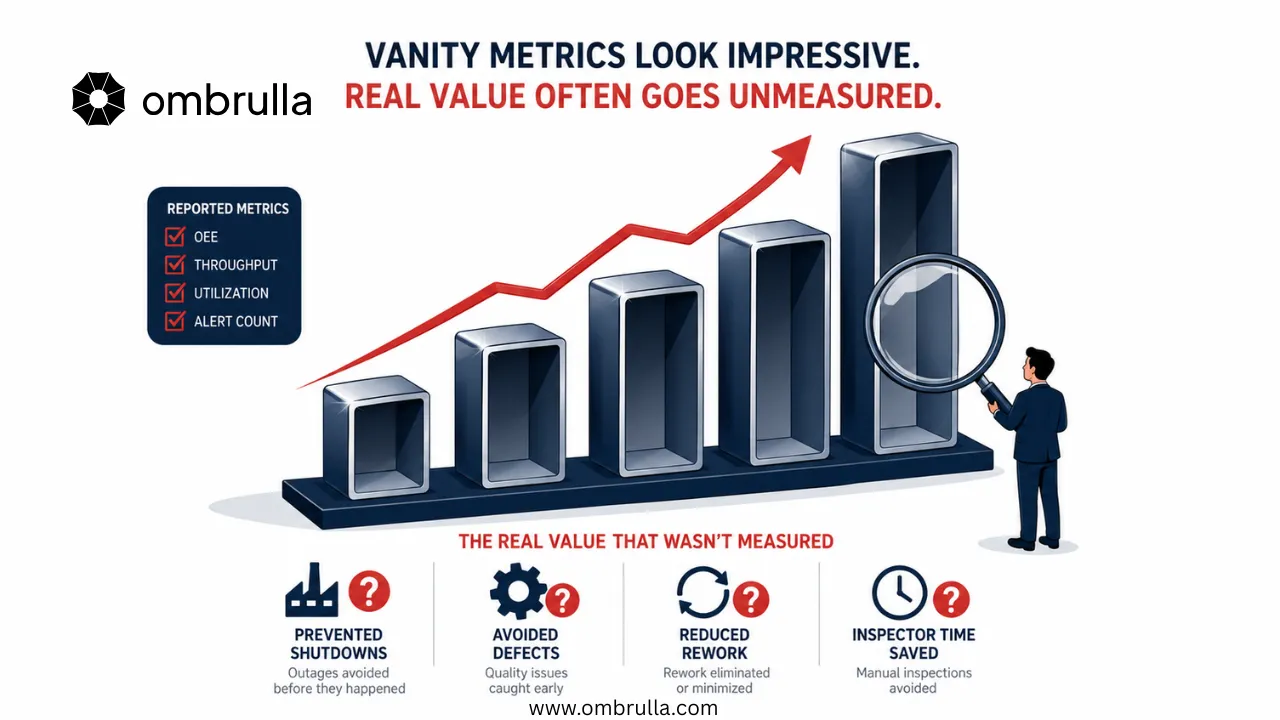
Industrial AI pilots frequently succeed on technical metrics and fail on business metrics. This is not a contradiction - it is a design flaw. When the success criteria for a pilot are defined by the AI team, they tend to reflect what AI teams care about: model accuracy, precision, recall, F1 scores, and processing latency. When the success criteria that matter to the business are defined by operations leaders, they look completely different: reduction in unplanned downtime, decrease in maintenance cost per asset, improvement in first-time quality rate, reduction in inspection hours per site visit.
The gap between these two sets of metrics is where business cases collapse. A pilot that achieves 93% defect detection accuracy in controlled conditions sounds impressive until a CFO asks: 'How many unplanned shutdowns did it prevent? What was the avoided maintenance cost? What is the payback period?' If the pilot was not designed to answer those questions, the AI programme loses its business case before it reaches the scaling decision.
The Vanity Metric Trap: A Comparison
| Metric Type | Vanity Metric (Pilot Focus) | Business Metric (CFO Focus) |
|---|---|---|
| Quality | Model accuracy: 94% | Defect escape rate reduction: 28% |
| Maintenance | Anomaly detection recall: 91% | Avoided unplanned shutdowns: 4 per year |
| Inspection | AI inference speed: 180ms | Inspection time per asset: -35% |
| Energy | Anomaly flagged 6 hours early | Energy cost saving: £180K/year |
| Safety | Defect classification mAP: 0.87 | Near-miss incidents prevented: 7 |
The McKinsey Global Institute 2023 AI adoption report found that organisations that defined business-outcome success criteria before starting AI pilots were 2.4 times more likely to successfully scale to production deployment than those that defined success in technical terms alone. The metric set is not a reporting preference, it is a survival mechanism for the business case.
What Successful Deployments Do Differently
Successful industrial AI programmes establish a 'business value equation' before the pilot launches: a defined relationship between AI model performance metrics and financial or operational outcomes. They designate a business owner for the AI programme, not just a technical sponsor, and require the business owner to sign off on the pilot success criteria. They also build a parallel 'shadow measurement' process that tracks avoided costs, saved hours, and prevented incidents throughout the pilot - creating a real business case from observed data, not retrospective estimates.
What [Successful Industrial AI Deployments](/usecases) Have in Common

The 13% of industrial AI programmes that successfully navigate from pilot to production deployment do not succeed by accident. Analysis of case study data from the Manufacturing Leadership Council, McKinsey, and the World Economic Forum's Advanced Manufacturing Initiative reveals a consistent set of organisational characteristics that separate scalable AI programmes from the 87% that stall.
| Success Pattern | What It Looks Like in Practice | Failure Pattern Contrast |
|---|---|---|
| Business-first problem definition | AI programme starts with a quantified business problem, not an AI technology looking for a use case | Technology-first: 'Let's do computer vision' without a specific outcome |
| Funded data engineering workstream | Data infrastructure investment precedes model training; OT data pipelines built before AI layer | Data 'assumed to be available'; data cleaning left to AI team during pilot |
| Production-mirroring pilot design | Pilot uses production-quality data, real edge cases, and actual integration paths from day one | Pilot uses best available data in controlled environment with manual data feeds |
| Operational champion at senior level | An operations director or VP owns the AI programme outcome - not just the IT or data science team | AI programme owned by IT or innovation team with no P&L accountability |
| Worker-inclusive design process | Frontline operators and inspectors contribute to AI model requirements, testing, and validation | Workers introduced to AI system at go-live without prior involvement |
| Continuous model governance | MLOps process established for model monitoring, drift detection, and retraining before pilot completes | No model governance plan; data science team disengaged after initial deployment |