

Why 2026 Is a Pivotal Year for Industrial AI PdM
The convergence of edge AI hardware, affordable MEMS sensors, open IIoT connectivity standards and mature machine learning frameworks has produced a step-change in what is achievable on the plant floor. In 2022, most deployments were still confined to pilot programmes on a handful of critical assets. In 2024, large manufacturers began rolling out AI PdM at scale. By mid-2026, according to multiple industry trackers, the global AI-in-predictive-maintenance market surpasses USD 9 billion - with compound annual growth rates exceeding 30%.
But scale has also brought hard lessons. Poorly configured systems generate alert fatigue. RUL predictions made without sufficient training data mislead maintenance planners. ROI projections built on vendor case studies rather than operational benchmarks disappoint CFOs. This report exists to cut through the noise.

CNC Machining Centres
Precision Manufacturing and the Cost of Unscheduled Stops
CNC machining centres - milling, turning, drilling and grinding machines - are the precision workhorses of automotive, aerospace and electronics manufacturing. Unlike pumps and compressors where failure typically means lost production time, CNC failures can also mean scrap production, tooling damage, workpiece rejection and jig or fixture damage. The cost picture is therefore more complex and, in many cases, significantly higher per event.
AI predictive maintenance for CNC is also technically distinct: the machine itself changes state constantly (different operations, tool paths, materials) making signal normalisation more complex and requiring more sophisticated contextual AI models.
Common Failure Modes - CNC Machines
| Failure Mode | Frequency | Primary Sensor Signal | Lead Time |
|---|---|---|---|
| Spindle bearing degradation | ~38% | Vibration + temperature | 5–18 days |
| Tool wear/breakage | ~30% | Current + acoustic emission | Minutes–hours |
| Feed drive ball screw wear | ~15% | Current + positional error | 20–60 days |
| Linear guide degradation | ~9% | Vibration (low freq.) | 30–90 days |
| Coolant system failure | ~8% | Temperature + flow | 2–7 days |

Key Sensor Parameters - CNC Machines
- - Vibration (spindle-mounted accelerometer, high-frequency): Gold standard for spindle bearing health. Defect frequencies at BPFI, BPFO and rolling element pass within 1–20 kHz are primary AI targets.
- - Motor current (spindle and feed drives): Tool wear monitoring. Gradual current increase indicates increasing cutting forces from tool degradation. Sudden spikes indicate tool breakage.
- - Acoustic emission (AE sensors, 100 kHz–1 MHz): Highly sensitive early detection of tool chip formation, micro-cracks and surface deformation. Cost-effective with modern MEMS AE sensors.
- - Positional feedback (servo encoder data): Ball screw and linear guide wear produces measurable positional error trends that AI models can detect through CNC controller data.
- - Thermal mapping (infrared or thermistor arrays): Spindle thermal drift compensation and coolant flow monitoring.
ROI Benchmarks - CNC Machines
- - Scrap reduction: 15–35% reduction in machining rejects from improved tool life management
- - Spindle repair/replacement avoidance: USD 25,000–120,000 per spindle rebuild avoided
- - Maintenance cost reduction: 22–38% compared with scheduled maintenance
- - Overall Equipment Effectiveness (OEE) improvement: 8–18 percentage points from unplanned downtime reduction
Alert Lead Time Analysis
Alert lead time - the window between an AI system's first alert and the point of functional failure - is perhaps the single most operationally significant metric in predictive maintenance. It determines whether there is sufficient time for parts procurement, scheduling and safe intervention.

| Asset | Failure Mode | Lead Time Range | Operational Significance |
|---|---|---|---|
| Pump | Bearing fault | 7–21 days | Typically sufficient for planned shutdown |
| Pump | Seal failure | 3–10 days | Tight window - parts pre-staging critical |
| Compressor | Valve wear | 3–8 days | Requires stocked spare valves on-site |
| Compressor | Oil degradation | 14–45 days | Comfortable planning window |
| CNC | Spindle bearing | 5–18 days | Spindle rebuild must be scheduled |
| CNC | Tool wear | Minutes–hours | Real-time intervention only |
| Transformer | Partial discharge | 60–365 days | Enables planned replacement programme |
| Transformer | Tap changer wear | 7–45 days | OLTC inspection can be planned |
Benchmark Insight: Untapped Lead-Time Potential
The gap between the first detectable degradation signal and the point of no return is often 3–5x longer than the gap between a typical AI alert and actual failure.
This means that many current PdM systems are still detecting failures later than technically possible. With improved signal processing, feature engineering, sensor fusion, and model tuning, AI systems can extend actionable maintenance lead times well beyond today’s benchmark averages.
ROI Model and Financial Framework
The Total Value Architecture of AI PdM
A robust ROI model for industrial AI PdM must capture value across four dimensions: direct cost savings, indirect operational benefits, risk mitigation and strategic advantages. Many organisations underinvest in AI PdM because their business cases only model direct maintenance cost savings, missing 60–70% of the total value.
| Value Category | Components | Typical % of Total Value |
|---|---|---|
| Direct Maintenance Savings | Labour, parts, consumables reduction | 25–35% |
| Downtime Avoidance | Lost production, restart costs, penalties | 35–45% |
| Asset Life Extension | Deferred capital replacement | 10–20% |
| Risk & Compliance | HSE incidents, environmental fines, insurance | 10–15% |
| Energy Efficiency | Optimised loading, reduced losses | 5–10% |
Simplified ROI Calculation Framework
The following formulas provide a reproducible starting point for building a site-specific AI PdM business case:
- - Annual Value = (N_assets × Avg_downtime_avoided_hrs × Production_rate_$/hr) + (N_assets × Avg_maintenance_saving_$/asset) + (Catastrophic_failure_probability × Consequence_cost_$) + (Energy_saving_% × Annual_energy_spend_$)
- - Net ROI (%) = (Annual Value − Annual Platform Cost) ÷ Total Implementation Cost × 100
- - Payback Period (Months) = Total Implementation Cost ÷ (Monthly Value − Monthly Platform Cost)

Benchmark ROI Data by Asset Class
| Asset Class | Impl. Cost Range | Annual Value Range | Typical Payback | 5-Year ROI |
|---|---|---|---|---|
| Pump (per unit) | $3k–15k | $18k–85k | 3–10 months | 400–900% |
| Compressor (per unit) | $8k–35k | $45k–250k | 4–12 months | 350–800% |
| CNC Machine (per unit) | $5k–25k | $25k–130k | 6–18 months | 250–650% |
| Transformer (per unit) | $15k–80k | $100k–2M+ | 6–24 months | 500–2000%+ |
Industry-Specific Recommendations
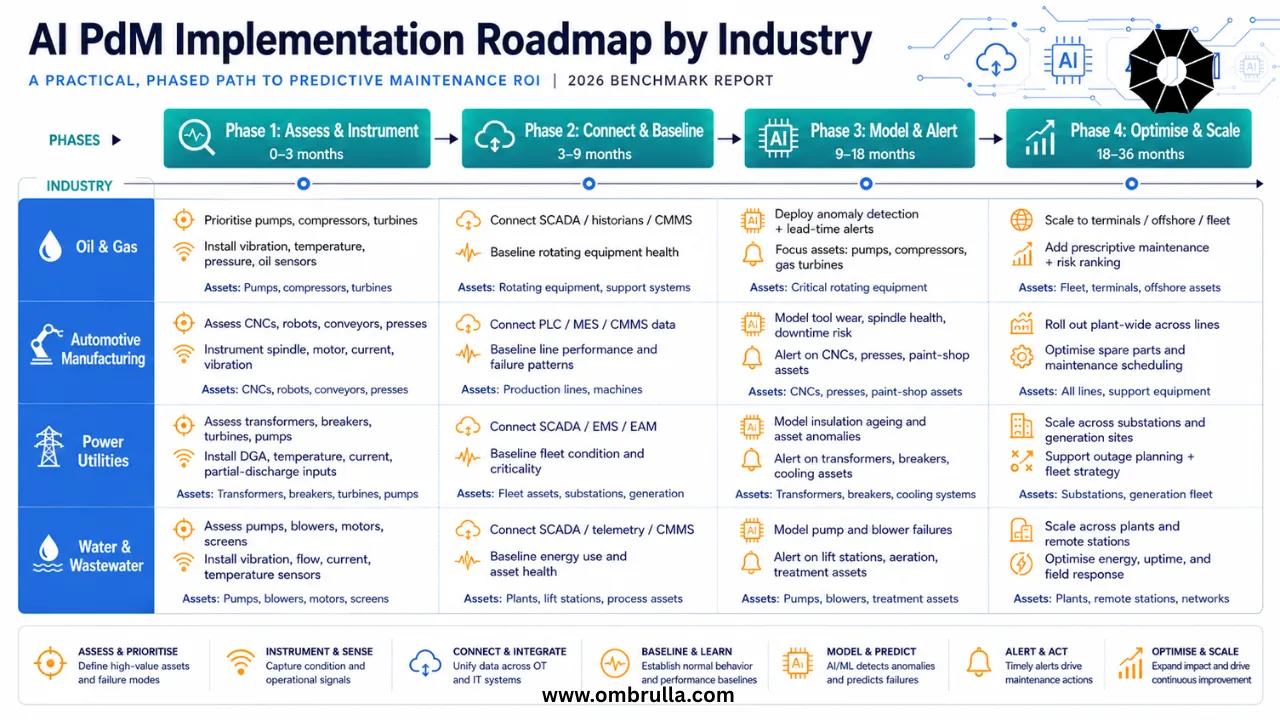
Oil & Gas / Petrochemicals
Priority Assets: Centrifugal pumps (crude, product, injection), gas compressors (centrifugal and reciprocating), rotating seals.
- - Start with high-consequence assets: Process-critical pumps and compressors where failure causes safety incidents or production shutdowns take priority over utility equipment.
- - Integrate with Process Safety Management (PSM) systems: AI PdM alerts should feed into HSE risk registers and permit-to-work workflows, not operate as standalone tools.
- - Explosion-proof sensor selection: ATEX Zone 1/2 (EU) or Class I Division 1/2 (US) certified sensors are mandatory - this constraint significantly narrows viable hardware options.
- - Oil analysis as foundation: Lubrication condition monitoring should be the first AI PdM layer deployed given the availability of existing oil sampling infrastructure at most refineries.
Automotive Manufacturing
Priority Assets: CNC machining centres (engine blocks, transmission components), transfer lines, compressed air systems, coolant pumps.
- - Integrate with OEE systems: AI PdM alerts should directly inform OEE calculations and feed into the daily operations meeting rhythm - positioning predictive maintenance as a production KPI, not a maintenance task.
- - Tool life management integration: Connect CNC AI PdM with the MES/ERP tool management module to automate tool replacement work orders based on AI wear signals rather than fixed-cycle rules.
- - Multi-machine fleet learning: Automotive plants often have banks of identical CNC machines. Deploy AI models that learn from the fleet collectively while maintaining per-machine baselines - dramatically reducing training data requirements.
- - Coordinate with model change cycles: AI model retraining requirements should be planned around vehicle model changeover periods to avoid baseline disruption.
Power Generation and Utilities
Priority Assets: Power transformers (transmission and distribution), cooling water pumps, gas/steam turbines, HV switchgear.
- - Prioritise DGA for transmission transformers: For assets rated 100 MVA and above, online DGA monitoring with AI interpretation should be considered standard practice, not optional.
- - Align with grid reliability frameworks: AI PdM programmes for utilities should be designed to support NERC CIP (North America) or equivalent reliability standard compliance documentation.
- - Seasonal load profiling: Transformer AI models must incorporate seasonal load variation patterns to avoid load-increase alerts during peak demand periods.
- - Substations as deployment units: Rather than asset-by-asset deployment, utilities achieve faster ROI by deploying AI PdM across all monitored assets within a substation simultaneously, enabling cross-asset correlation analysis.
Water and Wastewater Utilities
Priority Assets: Submersible and horizontal split-case pumps, blowers (WWTP aeration), UV disinfection systems.
- - Budget-constrained deployment: Water utilities typically operate under tighter capex constraints than industrial manufacturers. Prioritise sensor-light approaches: MCSA (motor current signature analysis) provides significant diagnostic value at low sensor cost.
- - Regulatory compliance integration: AI PdM alerts for treatment assets should integrate with SCADA systems and regulatory compliance reporting workflows.
- - Pump efficiency as primary KPI: For water utilities where energy is the largest operational cost, hydraulic efficiency monitoring (pump curve deviation) often delivers faster ROI than fault detection alone.
- - Remote monitoring for distributed assets: Water networks have geographically distributed pump stations. Prioritise cloud-connected edge AI platforms that minimise on-site infrastructure requirements.